

こんにちは、ヒガシです。
AIモデルを構築する際に、scikit-learnのStandardScalerを使ってデータを標準化(元データから平均を引いて、分散で割る)することはよくあると思います。
このページでは、StandardScaler内の処理で使われている平均値、分散値を取得する方法をご紹介していきます。
それではさっそくやっていきましょう!
サンプルデータを用意する
まずはデータがないと始まりませんので、有名なBostonの住宅価格のデータセットを使うことにします。
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
# ボストンデータセットの読み込み
boston = load_boston()
# ボストンデータセットのデータフレームの作成
df = pd.DataFrame(boston.data, columns=boston.feature_names)
# 目的変数(PRICE)をデータフレームに結合
df['PRICE'] = np.array(boston.target)
#データをnumpy配列に格納
data = df.values
#データを表示してみる
print('Before_Standardization', data)
これで変数dataの中に標準化前のデータが格納されています。

scikit-learnのStandardScalerでデータを標準化する
それでは本題であるデータの標準化に入っていきましょう。
#sklearnで平均と分散を取得する
scaler = StandardScaler()
scaler.fit(data)
data_st = scaler.transform(data)
print('After_Standardization', data_st)
標準化作業としてはたったのこれだけです。
以下が標準化後のデータの中身です。

標準化前はデータごとに桁が異なっていましたが、標準化後は似たような数値に収まってくれていますね。
標準化処理で使われた平均値と分散値を確認する方法
次に先ほどの処理の中で使われた平均値と分散値を確認する方法をご紹介します。
以下がそのやり方です。
print('ave_sklearn:', scaler.mean_)
print('std_sklearn:', scaler.scale_)
超簡単ですね。
以下の結果が出力されました。
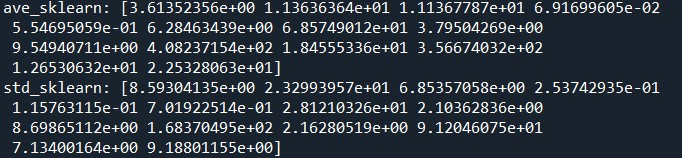
問題なく出力されていそうですね。
numpyを使って確認計算してみる
念のため先ほど出力された結果を検算してみましょう。
numpyを使って各ラベルの平均値、分散値を取得して比較してみます。
#numpyで平均と分散を計算してみる
mean = []
std = []
for i in range(data.shape[1]):
mean.append(np.mean(data[:,i]))
std.append(np.std(data[:,i]))
mean = np.array(mean)
std = np.array(std)
print('ave_numpy:', mean)
print('ave_numpy:', std)
以下の結果が出力されました。
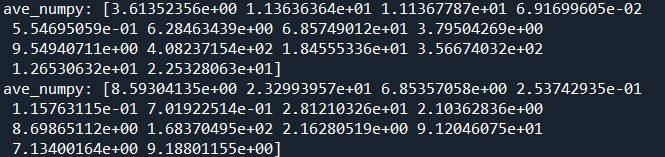
scikit-learnの結果も再掲します。
両者は完全に一致していますね。
おわりに
というわけで今回はscikit-learnのStandardScalerを使ってデータを標準化した際に平均値と分散値を取り出す方法をご紹介しました。
学習後のAIモデルを別の環境に移植する際などにこの処理はよく必要になりますので、ぜひやり方を覚えておきましょう!
このブログでは、このようなAIスキルを多数紹介しています。
ぜひ他のページもご覧ください。
それではまた!

コメント