


この記事では、pandasを使って読み込んだcsvデータに対して、指定した列内で条件に当てはまるデータ数を数える方法をご紹介していきます。
今回紹介する内容を習得し、データの中身を確認できるようになりましょう。
それではさっそく本題に入っていきます。
使用するデータの内容確認
今回は以下のcsvファイルを使用します。
系列でいろいろなデータが出力されているものですね。
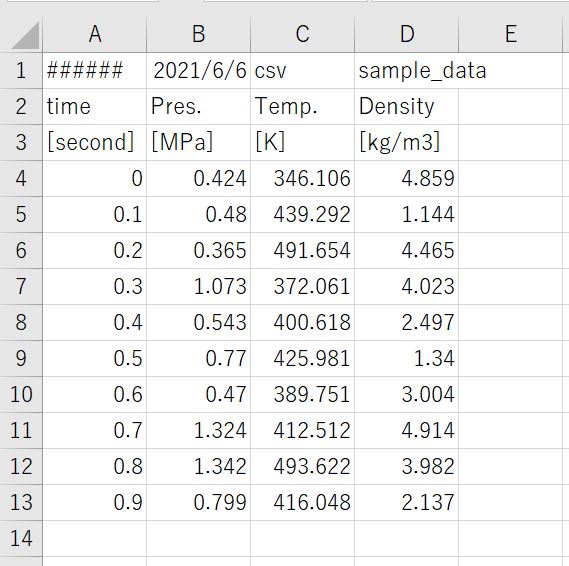
今回はこのデータの3列目にあるTemp.の項目が400K以上のデータが何個あるかをpythonプログラム上で確認してみましょう。
(数えたところ7つありますね。というわけで7が出力できればOKですね。)
なお、このcsvファイルは以降で紹介するpythonコードと同じフォルダに保存されていることします。
別の場所にcsvファイルがある場合は適宜コードを修正しましょう。
指定列内で条件に当てはまるデータ数を数える方法
やりたいことがわかったところで、実際の作業にはいっていきましょう。
さっそくですが、以下がその実行コードです。
#ライブラリのインポート
import pandas as pd
#データの読み込み
data = pd.read_csv('sample_data.csv',skiprows=[0,2])
#読み込んだデータを表示する
print(data)
#ヘッダーの確認
print(data.columns)
#条件に当てはまるデータ数を算出
nT400 = (data['Temp.'] > 400).sum()
#結果を表示
print('num_data='+str(nT400))
こいつを実行すると以下の結果が得られました。
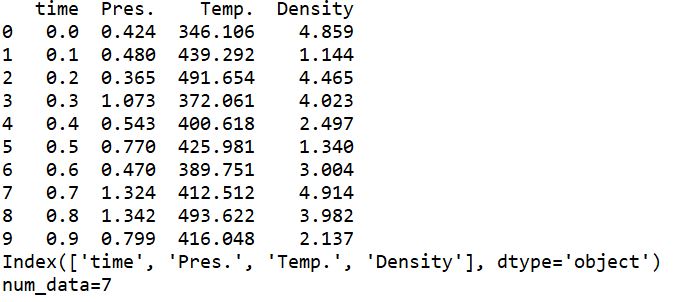
問題なく、最終的に目的の7という数値を出力できていますね。
なお、今回はcsvのヘッダーが3行あるデータを使用したので、データ読み込み時にそれらの一部をスキップする処理を行っています。
以下の記事に詳細を記載していますので、興味があればこちらもご覧ください。
【python-pandas】複数行ヘッダーを持つcsvファイルの読み込み処理
算出条件を変更して再実行
だいたいやりかたはわかったと思いますので、他の条件も数えれるかどうか確認してみましょう。
次は圧力が1.0MPa以上のものを数えてみましょう。
⇒3が出力されればOKですね。
(もう一度先ほどのcsvファイルの中身を表示しておきます。)
ではコードを書き換えてみましょう。
#ライブラリのインポート
import pandas as pd
#データの読み込み
data = pd.read_csv('sample_data.csv',skiprows=[0,2])
#読み込んだデータを表示する
print(data)
#ヘッダーの確認
print(data.columns)
#条件に当てはまるデータ数を算出
nP1 = (data['Pres.'] > 1.0).sum()
#結果を表示
print('num_data='+str(nP1))
結果は以下の通りですね。
こちらも問題なさそうですね。
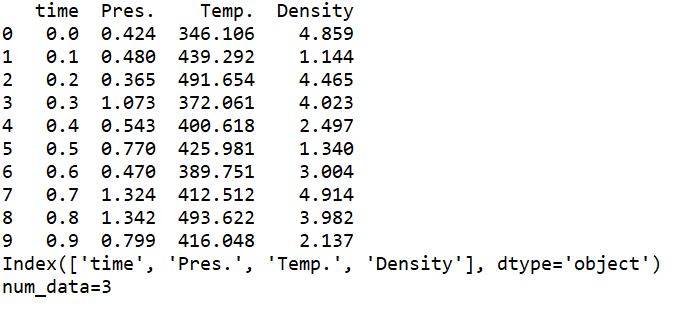
ヘッダー部分の指定と条件式を書き換えるだけですね。
ぜひ自分で何かしらのデータを準備して練習してみましょう。
おわりに
というわけで今回はpythonのpandasで読み込んだデータに対して、指定列内で条件に当てはまるデータ数を数える方法をご紹介しました。
AIに与えるデータの前処理時にぜひご活用ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント