

こんにちは、ヒガシです。
TensorflowやPytorchの環境下でAIモデルを構築しても、実際に運用する際にそれらの環境を準備できないことってよくありますよね。
そんな状況に対応するために以前の記事にて、単純な多層パーセプトロン(MLP)モデルをnumpyの行列計算のみで再現する方法をご紹介しました。
【AI】活性化関数付MLPモデルの計算を行列計算で再現する方法!
今回は時系列データを取り扱うのがLSTMモデルに同じ処理を適用してみようと思います。
それではさっそくやっていきましょう!
KerasでLSTMモデルを構築する
LSTMの内部計算を再現しようにも、まずは学習済みのモデルがないと話になりません。
というわけでまずは簡易的なLSTMモデルを構築するところから始めます。
今回は以下のデータを用います。
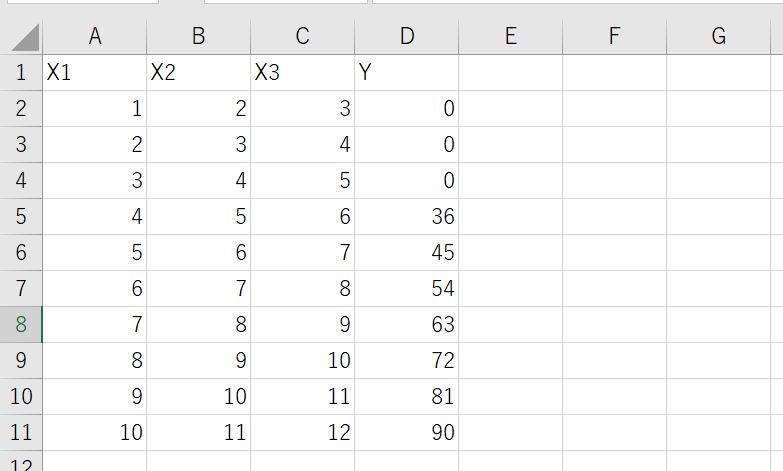
LSTMのLook Back数を4にとり、X1,X2,X3を一つの時刻における入力、Yをその時刻における出力としてモデルを構築していきます。
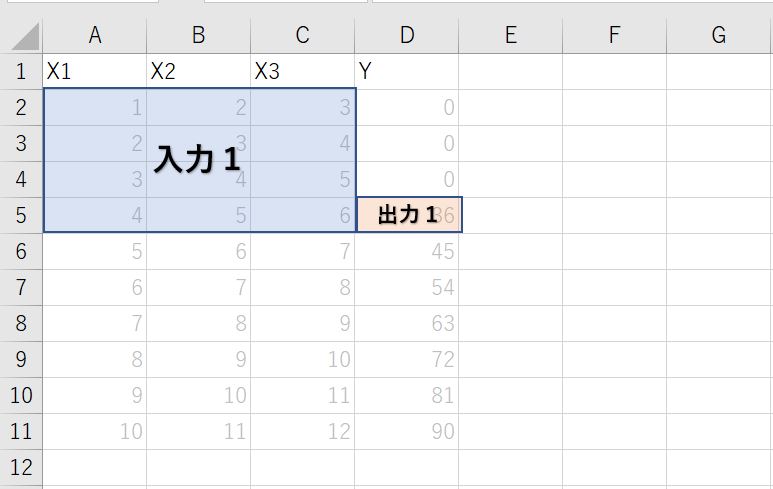
なので以下のように7つのデータを学習させることになります。
★1つ目のデータ
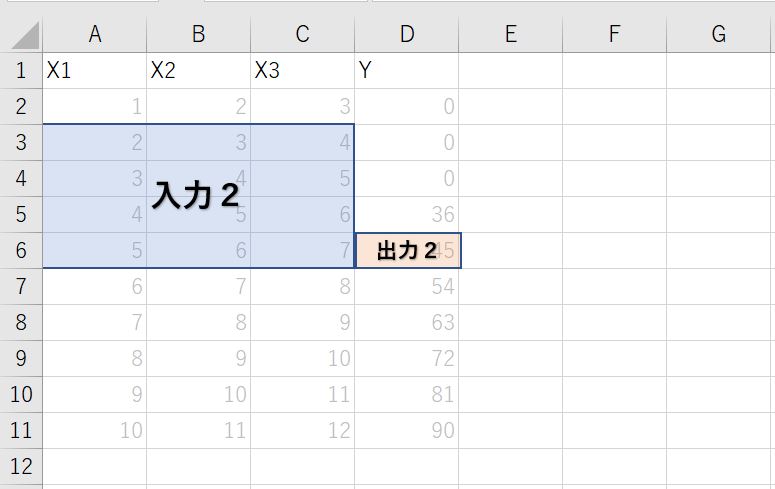
★2つ目のデータ
★7つ目のデータ

今回はモデルを作ることが目的ではなく、あくまでもLSTMモデルの内部計算を行列計算だけで実施することが目的ですので、このような簡易的なデータを用いていきます。
それでは上記データが入ったcsvファイルがプログラム実行フォルダに【LSTM_sample.csv】という名前で保存されていることを前提に、LSTMモデルを構築していきましょう。
以下がそのコードです。
#ライブラリインポート
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import Adam
#csvファイルの読み込み
data_file='LSTM_sample.csv'
data=pd.read_csv(data_file).values
#学習用データセットの構築
Xdata=[]
Ydata=[]
look_back=4
for i in range(data.shape[0]-look_back+1):
Xdata.append(data[i:i+look_back,:-1])
Ydata.append(data[i+look_back-1,-1])
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
#LSTMモデルの構築
hl_unit=3
model = Sequential()
model.add(LSTM(hl_unit, input_shape=(look_back,Xdata.shape[2])))
model.add(Dense(1))
model.compile(loss="mean_absolute_error", optimizer=Adam(lr=0.01))
model.summary()
history=model.fit(Xdata,Ydata,batch_size=4,epochs=2000)
これで変数modelの中にLSTMモデルが構築できます。
Keras-LSTMモデルの内部パラメーターを取得する
モデルが構築できたら、次はLSTMモデルが学習した内部のパラメータを取得していきましょう。
以下がそのコードです。
#LSTM内部の重み、バイアスを取得
W,U,b,Wout,bout=model.get_weights()
これで各変数の中にLSTM内部で使用する重み、バイアスが格納されます。
ここまでがKeras環境で実施する内容になります。
LSTMの内部パラメータを行列計算用に分解する
LSTM内部の計算をnumpyの行列計算だけで再現する事前準備として、まずは先ほど取得したパラメーターを行列計算用に分解します。
以下がそのコードです。
#内部パラメータを行列計算用に分解する
Wi=W[:,0:hl_unit]
Wf=W[:,hl_unit:2*hl_unit]
Wc=W[:,2*hl_unit:3*hl_unit]
Wo=W[:,3*hl_unit:]
Ui=U[:,0:hl_unit]
Uf=U[:,hl_unit:2*hl_unit]
Uc=U[:,2*hl_unit:3*hl_unit]
Uo=U[:,3*hl_unit:]
bi=b[0:hl_unit]
bf=b[hl_unit:2*hl_unit]
bc=b[2*hl_unit:3*hl_unit]
bo=b[3*hl_unit:]
分解後のそれぞれのパラメータが何を意味しているかは別途解説していますので、今回はとりあえずこうゆう作業が必要なんだと飲み込んでいただけると幸いです。
詳細が気になる方は以下をご覧ください。
【AI】Keras-LSTMモデルの内部パラメータの意味を詳細解説!
LSTMの内部計算をnumpyだけで実行する方法
事前準備はここまで。
それでは本題であるLSTMの内部計算の再現をしていきましょう。
以下がそのコードです。
#シグモイド関数を定義
def sigmoid(x):
return(1.0/(1.0+np.exp(-x)))
#numpy計算とKerasの結果を比較する
result=[]
for index in range(Xdata.shape[0]):
c=np.zeros(hl_unit)
h=np.zeros(hl_unit)
#LSTMの内部計算部分
for i in range(Xdata.shape[1]):
x=Xdata[index][i]
it=sigmoid(np.dot(x,Wi)+np.dot(h,Ui)+bi)
ft=sigmoid(np.dot(x,Wf)+np.dot(h,Uf)+bf)
ctt=np.tanh(np.dot(x,Wc)+np.dot(h,Uc)+bc)
ot=sigmoid(np.dot(x,Wo)+np.dot(h,Uo)+bo)
c=ft*c+it*ctt
h=np.tanh(c)*ot
manual_result=np.dot(h,Wout)+bout
keras_result=model.predict(np.array([Xdata[index]]))
result.append([keras_result,manual_result])
#結果の可視化
result=np.array(result)
plt.scatter(result[:,0],result[:,1])
plt.xlabel('Keras_Predic',fontsize=14)
plt.ylabel('Manual_Calc',fontsize=14)
numpy計算とKerasの結果を比較した結果
それでは先ほどのコードで実施した、numpyでのLSTMモデルの再現と、Kerasを使って計算した結果を比較してみましょう。
以下がその結果です。
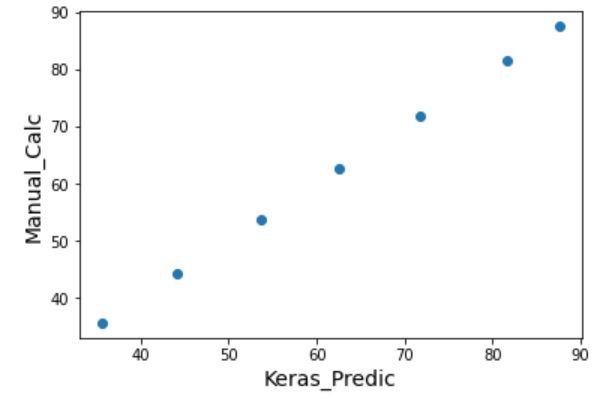
numpy計算とKerasの計算は見事に一致していますね。
というわけで問題なくやりたいことを実施できました。
おわりに
というわけで今回は時系列データを取り扱うのが得意なLSTMモデルの内部計算をnumpy行列計算のみで再現する方法をご紹介しました。
ライブラリが活用できない環境下でのAI運用の際などにぜひご活用ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント