

こんにちは、ヒガシです。今回は前回紹介したLSTMでの未来予測のリベンジ編です。
まずは前回のおさらいです。
前回は以下の画像に示しているように、LSTMモデルを使った短期の未来予測を繰り返し、長期の未来を予測するということをトライしてみました。
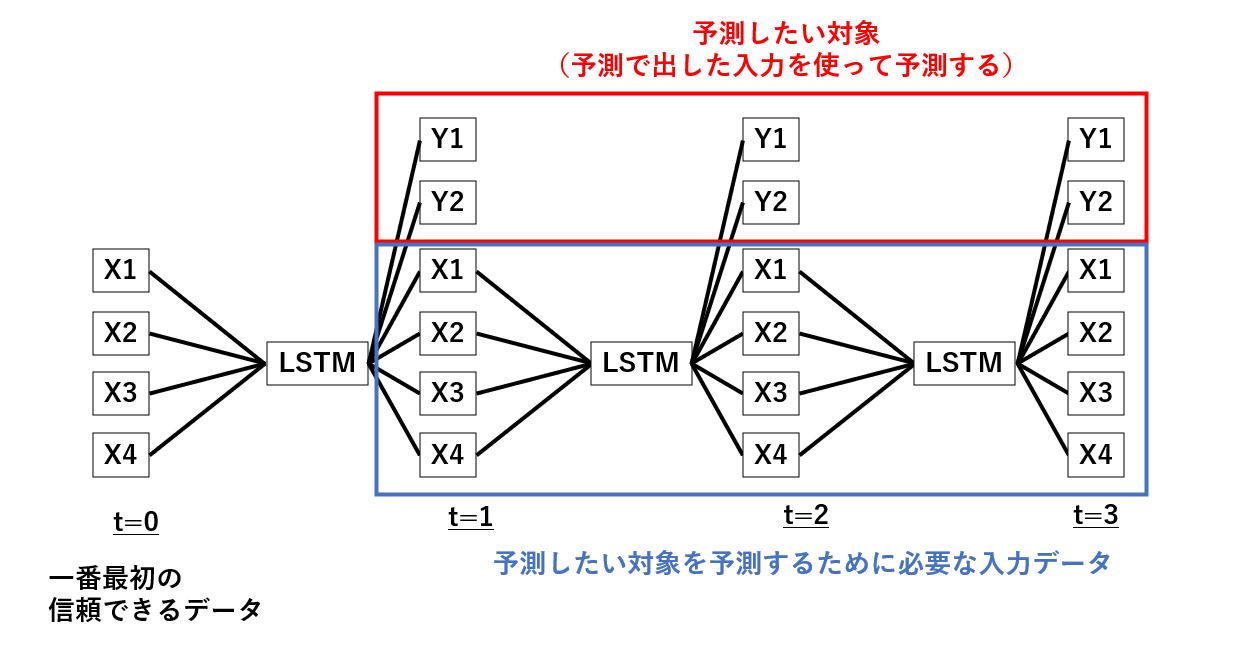
しかしながら最初はうまくいくものの、途中から徐々に精度が悪化するという結果でした。
以下がそのときの結果です。(赤が正解データ、青が未来予測で計算した結果です。)
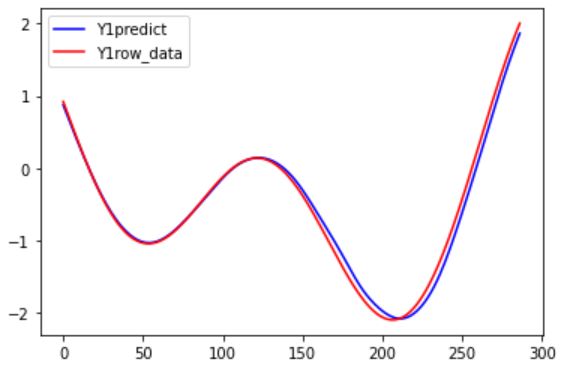
今回はこいつのリベンジをしたいと思います。
というわけでさっそく本題にはいっていきましょう!
長期未来予測の精度改善手法のご紹介
前回からの変更点はたったの一つだけです。
前回は以下の画像のように未来におけるデータの絶対値を予測していました。
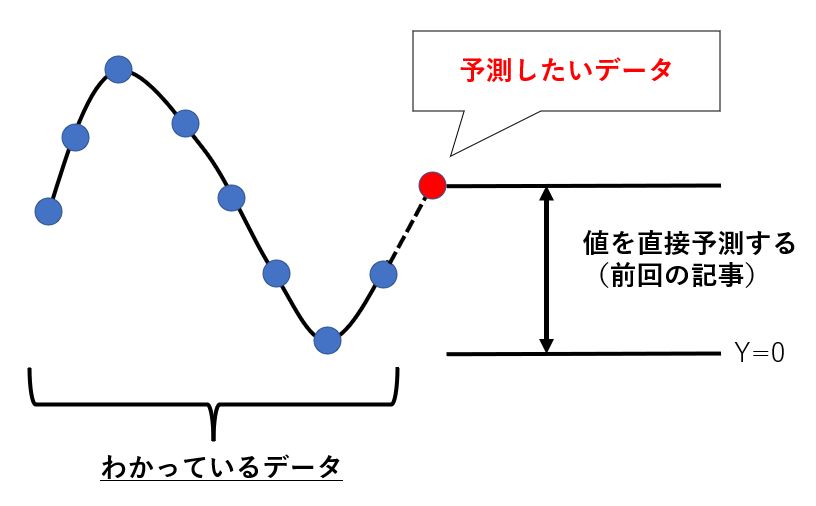
それに対して今回は以下のようにわかっている最後のデータからの差分を予測しにいくという手法に変更してみます。
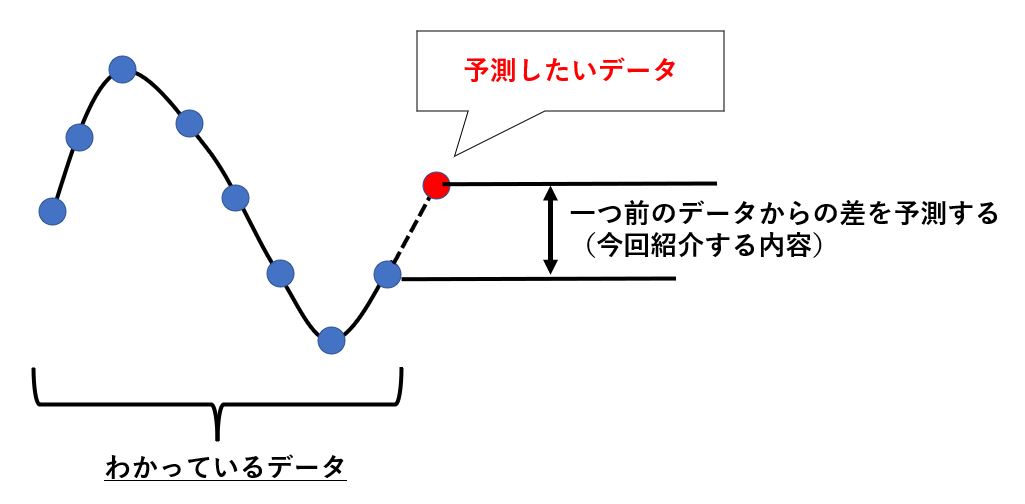
こうすることで出てくるデータはある程度信頼できるデータに近いものになるはずですから、前回のようにいきなり値がぶっとんでいくということは起こりにくいのではないかと予想されます。
というわけで以降はそのプログラムを実際に書いていってみましょう。
差分予測による未来予測:データ生成編
まずはデータの生成から始めましょう。
以下がそのサンプルコードです。
使用するデータは前回と同じなので、読み込んでいるcsvファイルに何が記載されているかは前回の記事を参考にしてください。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#時系列csvファイルの読み込み
data_file='data_set.csv'
data=pd.read_csv(data_file).values
data=data[:,1:]
input_data=data[:,0:4]
output_data=data[:,0:6]
Xdata=[]
Ydata=[]
Y2data=[]
look_back=5
#LSTM用にデータ生成
for i in range(data.shape[0]-look_back):
Xtimedata=[]
for j in range(input_data.shape[1]):
Xtimedata.append(input_data[i:i+look_back,j])
Xtimedata=np.array(Xtimedata)
Xtimedata=Xtimedata.transpose()
Xdata.append(Xtimedata)
Ytimedata=[]
Y2timedata=[]
for j in range(output_data.shape[1]):
#現在と次の時刻との差分をとっている
Ytimedata.append(output_data[i+look_back,j]-output_data[i+look_back-1,j])
#次の時刻の生値をとっている
Y2timedata.append(output_data[i+look_back,j])
Ydata.append(Ytimedata)
Y2data.append(Y2timedata)
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
Y2data=np.array(Y2data)
これでXdataのなかに現時点でのデータ、Ydataのなかに現時点でのデータと次の時刻でのデータの差分データ、Y2dataのなかに次の時刻でのデータが入っています。
※Y2dataは基本的に一番最初の時刻のデータしか使いませんが、未来予測した結果が正しいかどうかを比べるために全時刻で作成しています。
差分予測による未来予測:モデル構築編
それでは先ほど作成したデータをLSTMモデルに入力してみましょう。
以下がそのサンプルコードです。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import Adam
Xdim=Xdata.shape[2]
Ydim=Ydata.shape[1]
#モデル構築⇒学習開始
validation_split_rate=0.2
model = Sequential()
model.add(LSTM(4, input_shape=(look_back,Xdim)))
model.add(Dense(Ydim))
model.compile(loss="mean_squared_error", optimizer=Adam(lr=0.001))
model.summary()
history=model.fit(Xdata,Ydata,batch_size=16,epochs=500,validation_split=validation_split_rate)
#学習結果の描写
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
こいつを実行すると以下のグラフが出力されました。
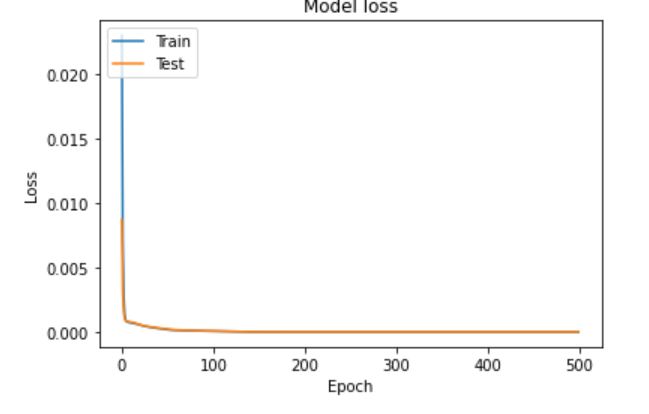
問題なくロスが減っていますね。
差分予測による未来予測:テスト編
それでは先ほど構築したモデルを使って実際に長期未来予測を行っていきましょう!
基本的にやろうとしていることは以下の通りです。
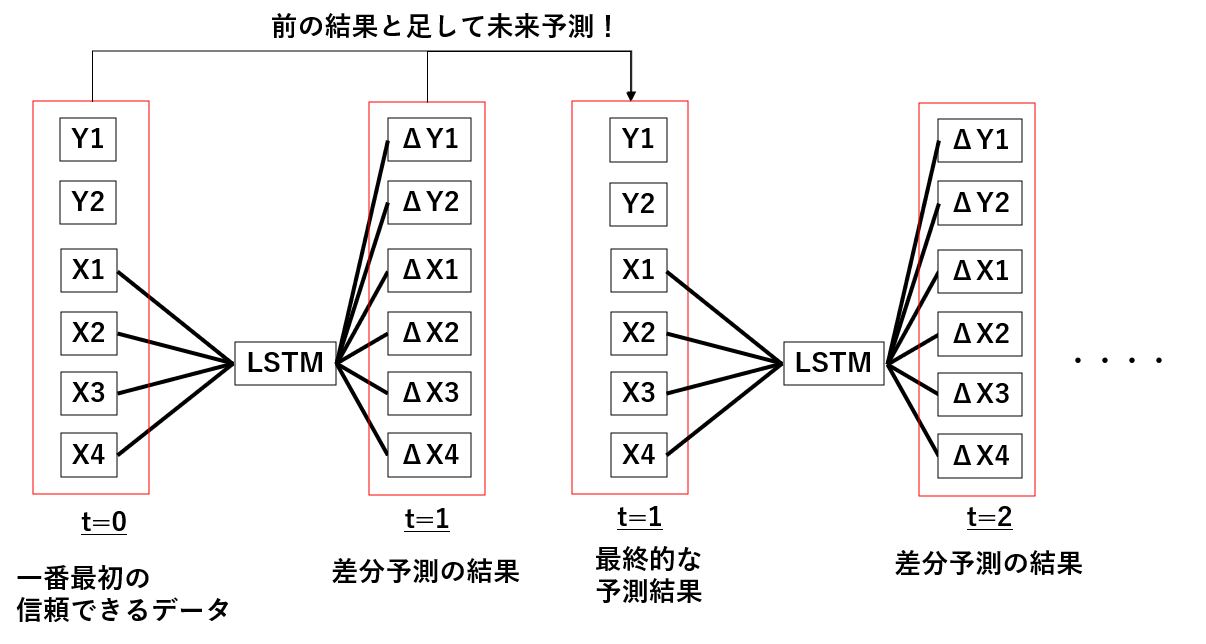
こんな感じで出てきた差分データを一個前のデータと足し合わせることで、次の時刻を予測するための入力データを作っていく、ということを繰り返し行っていきます。
以下がそのサンプルコードです。
#学習に使っていないデータを抜き出す
Xdata_validation=Xdata[-int(len(Xdata)*(validation_split_rate)):]
Ydata_validation=Y2data[-int(len(Ydata)*(validation_split_rate)):]
#最初の入力、出力データを生成する
first_input=Xdata_validation[1]
first_output=Ydata_validation[0]
new_Ydata=[]
#長期未来予測開始
for i in range(Ydata_validation.shape[0]):
Predictdata = model.predict(np.array([first_input]))
Predictdata= Predictdata+first_output
next_input=np.concatenate([first_input,Predictdata[0,:4].reshape(1,4)],0)[1:,:]
first_input=next_input
new_Ydata.append(Predictdata)
first_output=Predictdata
new_Ydata=np.array(new_Ydata)
これでnew_Ydataに最初の時刻だけを使って長期の未来を予測した結果が入っています。
それでは以下のコードで正解と予測結果を比較してみましょう。
plt.plot(range(0, len(new_Ydata)),new_Ydata[:,0,4], color="b", label="Y1predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,4], color="r", label="Y1row_data")
plt.legend()
plt.show()
plt.plot(range(0, len(new_Ydata)),new_Ydata[:,0,5]+0.01, color="g", label="Y2predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,5], color="y", label="Y2row_data")
plt.legend()
plt.show()
結果はいかに?!?!
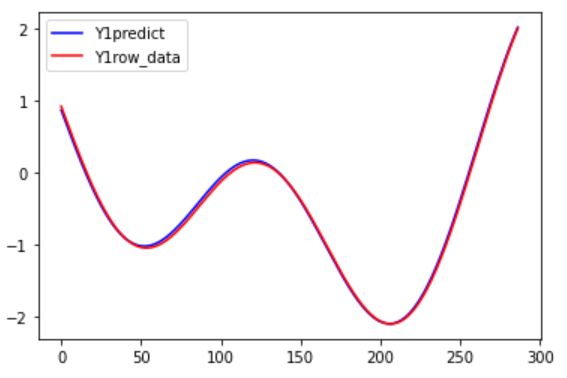
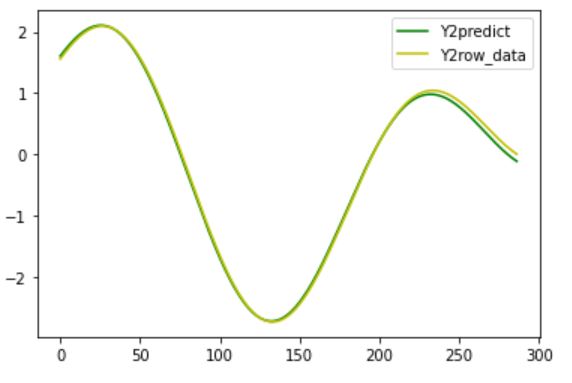
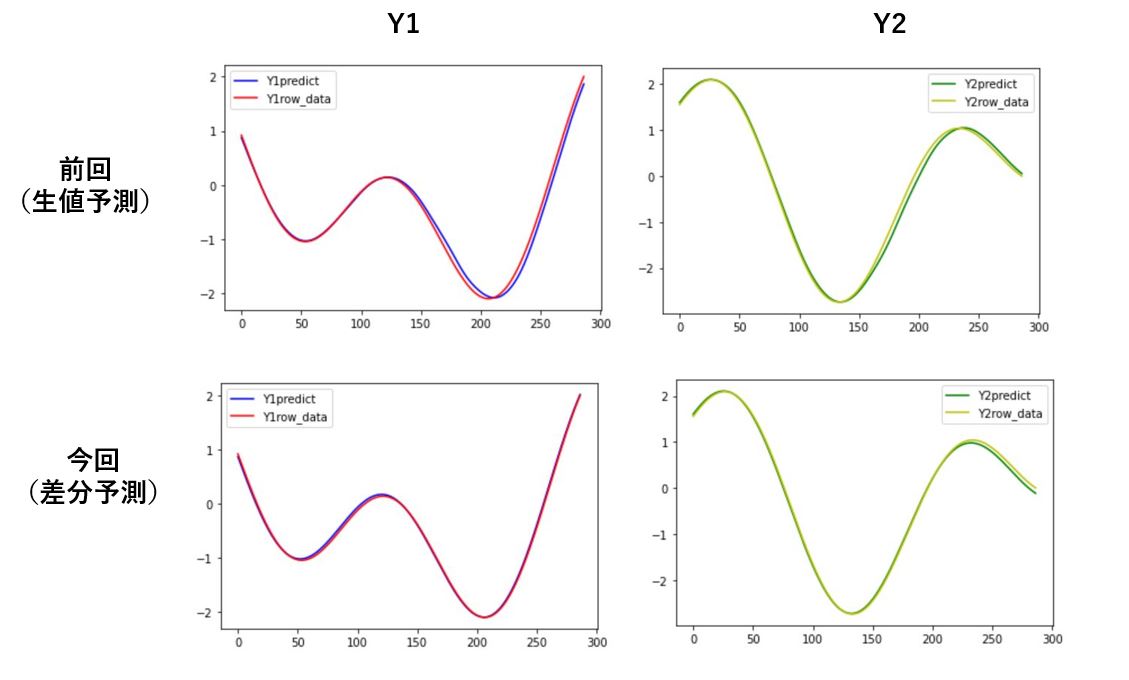
前回の結果との比較です。
こんな感じで少しは精度が良くなった気がしますね。
おわりに
というわけで今回は現在時刻と未来との差分を予測することで、長期未来予測の精度改善を試みました。
未来の値そのものを予測するよりもかなり精度改善ができましたね。
AI活用の際などにぜひご活用ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント