


こんにちは、ヒガシです。
今回はAIを構築する際に必要なデータ構築スキルについて解説していきます。
画像認識のAIを構築する際など、当然ながら大量の画像データをAIに学習させる必要があります。
一言に学習させると言っても、画像をフォルダに入れて終わりではありません。
AIが正しく認識できるような形式に事前に整えてあげる必要があります。
⇒今回はその事前に形式を整える作業がどのようなものなのかを解説していきます。
それではさっそくやっていきましょう。
※この記事ではPythonをつかって実装していきます。
また、私は普段AIを構築する際はKerasというライブラリを使って実装しています。
今回は普段私がやっている内容を再現するだけですので、他のライブラリで同じことをやってきちんと動くかはわかりません。その点はご了承ください。
事前準備:画像をフォルダに保存しておく
今回は過去のブログ記事にて使った以下の10枚の画像を使って実演していきます。
これらの画像はプログラムが保存されている場所と同じフォルダにあるtest55というフォルダに保存されていることとします。
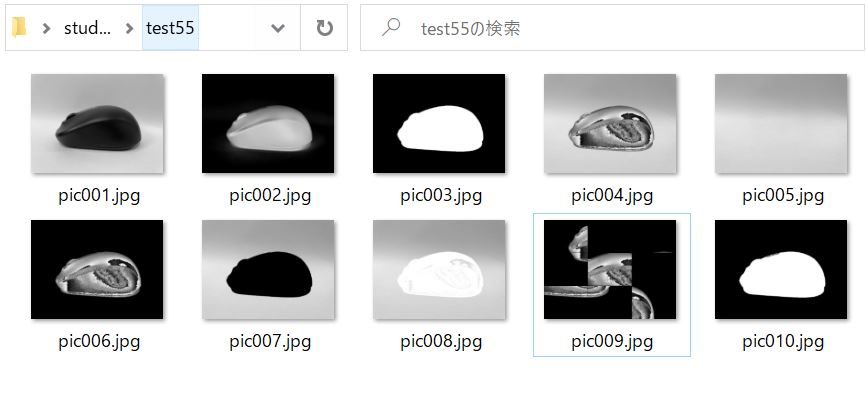
ちなみにこれらの画像はサイズがすべて縦581ピクセル、横773ピクセルで一致しています。
もし画像サイズが違う場合は、以降で紹介するサンプルコードにサイズを整える工程が必要になります。
状況に応じて適宜変更してください。
必要なライブラリ
今回は以下の2つのライブラリを使用して画像データセットを作成していきます。
インストールしていない方はまずはインストールしておきましょう。
〇openCV
〇numpy
〇glob
画像、ライブラリの準備できたら実際のコーディング作業に入っていきましょう。
AI用の画像データセットを構築するサンプルコード
早速ですが、以下がそのサンプルコードです。
#ライブラリのインポート
import cv2
import numpy as np
import glob
#画像保存場所を指定⇒フォイル名一覧を取得
pic_dir='test55/pic*'
pic_names=glob.glob(pic_dir)
#データセットの構築
data_set=[]
for i in range(len(pic_names)):
pic_data=cv2.imread(pic_names[i],cv2.IMREAD_GRAYSCALE)
data_set.append(pic_data)
data_set=np.array(data_set)
たったのこれだけです。
※コメントをつけていますので、それぞれの行で何を行っているのかを追いかけてみましょう。
念のためここで作ったdata_setの大きさを確認してみましょう。
配列の大きさを確認するには、以下のコードを実行します。
data_set.shape
すると以下の結果が出力されました。
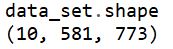
10が画像の枚数、581が画像の縦ピクセル数、773が画像の横ピクセル数を表しています。
ちなみに、今回は白黒画像なので2次元配列でしたが、もしこれがカラー画像として作成された場合だと以下のようになります。
要はBGRの3要素が追加されているわけですね。

※カラー画像配列を読み込みたい場合は先ほどのコードのcv2.IMREAD_GRAYSCALEの部分をcv2.IMREAD_COLORにすればOKです。
このようにして作ったdata_setという配列をKerasなどのライブラリに放り込んでやれば、AIは簡単に構築できてしまいます。
また、今回の内容をよく理解するうえで知っておいた方が良いことを以下の記事で解説しています。
興味があればこちらもぜひご覧ください。
【python】フォルダ内ファイルを一括取得!ワイルドカードも使用可!
【python-openCV】カラー画像の配列概念を事例を用いて徹底解説!
おわりに
というわけで今回は、AIに画像データを学習させる際のデータセットの作り方を簡単にご紹介しました。
あなたのAI開発において少しでも参考になっていれば幸いです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント