

こんにちは、ヒガシです。
このブログでは、これまでに様々なAIスキルを紹介してきたわけですが、その多くはKeras(Tensorflow)を用いて行ってきました。
というのも私の会社では多くの人がとっかかりやすいKerasで業務を行っており、私もその流れに乗らざるを得なかったためです。
しかしながら昨今のPytorch人気を見ていると、
「これはPytorchも扱えるようになっておかなければ世の中に置いて行かれる」
という危機感を抱くようになってきました。
ということで今回はPytorchの練習がてら定番ではありますがMNISTの手書き文字の分類問題をPytorchで実装していこうと思います。
構築したPytorch環境の紹介
今回は以下の環境を構築しました。
Pytorch : 2.2.1+cu118
Python : 3.10.13
環境構築は会社の新入社員サポートでさんざん経験しているので、このあたりはすんなり終わりました。
MNISTの画像認識サンプルコード
それでは前置きはこのくらいにして、さっそくPytorchでのサンプルコードです。
(だいたいのことは把握できているのでChatGPT君にサクッと書いてもらって、ちょっとした手直しした程度だけですが。)
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchsummary import summary
import numpy as np
# デバイスの設定(GPUが利用可能な場合はGPUを、そうでない場合はCPUを使用)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# データの前処理
transform = transforms.Compose([
transforms.ToTensor(), # 画像をテンソルに変換
transforms.Normalize((0.5,), (0.5,)) # データを正規化
])
# 訓練データセットの読み込み
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=0)
# テストデータセットの読み込み
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=0)
# ニューラルネットワークの定義
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 512) # 入力画像サイズ: 28x28, 出力サイズ: 512
self.fc2 = nn.Linear(512, 512) # 入力サイズ: 512, 出力サイズ: 512
self.fc3 = nn.Linear(512, 10) # 入力サイズ: 512, 出力サイズ: 10 (0~9の数字分類)
def forward(self, x):
x = x.view(-1, 28 * 28) # 画像を1次元に平坦化
x = F.relu(self.fc1(x)) # ReLU活性化関数を適用
x = F.relu(self.fc2(x)) # ReLU活性化関数を適用
x = self.fc3(x) # 出力層への入力
return x
net = Net().to(device)
summary(net,(1,28,28))
# 損失関数と最適化手法の定義
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# モデルの訓練
nb_epoch = 5
train_loss_list = []
train_acc_list = []
val_loss_list = []
val_acc_list = []
for epoch in range(nb_epoch):
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
#train
net.train()
for i, (images, labels) in enumerate(trainloader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
train_loss += loss.item()
train_acc += (outputs.max(1)[1] == labels).sum().item()
loss.backward()
optimizer.step()
avg_train_loss = train_loss / len(trainloader.dataset)
avg_train_acc = train_acc / len(trainloader.dataset)
#val
net.eval()
with torch.no_grad():
for images, labels in testloader:
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
val_acc += (outputs.max(1)[1] == labels).sum().item()
avg_val_loss = val_loss / len(testloader.dataset)
avg_val_acc = val_acc / len(testloader.dataset)
print ('Epoch [{}/{}], loss: {loss:.4f} val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}'
.format(epoch+1, nb_epoch, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc))
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
val_loss_list.append(avg_val_loss)
val_acc_list.append(avg_val_acc)
print('Finished Training')
# モデルのテスト
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
#学習履歴の出力
plt.plot(train_loss_list, color='blue' ,label='loss')
plt.plot(val_loss_list, color='orange', label='val_loss')
plt.legend(loc='upper right', fontsize=10)
plt.xlabel('epochs', fontsize=10)
plt.ylabel('loss', fontsize=10)
plt.show()
plt.plot(train_acc_list, color='blue' ,label='acc')
plt.plot(val_acc_list, color='orange', label='val_acc')
plt.legend(loc='lower right', fontsize=10)
plt.xlabel('epochs', fontsize=10)
plt.ylabel('loss', fontsize=10)
plt.show()
これでデータの準備、学習、学習履歴の表示、テストまでをぶっ通しで実行できます。
こんな感じで問題なく学習できました。
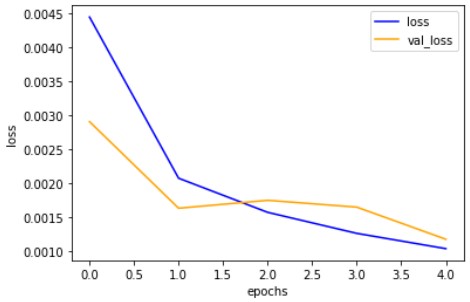
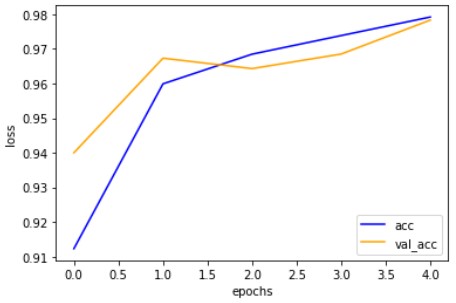
Kerasと比較しての感想
まずネットワーク定義の部分に関しては、Kerasと比較するとパラメータの数を自分で一つ一つ設定する必要があるのでやや面倒ではありますが、こっちの方が何をやっているのかを理解するうえでは良いと思います。
実際Keras使いが多い社内にはモデルを作ることはできるが、内部でどのようなことが行われているかを理解している人が少ないと感じていて、これはKerasがあまりにも簡単にネットワーク定義できてしまうことに起因していると私は思っています。
次に学習部分に関しては、ここは一度書いてしまえばほぼコピペで使える部分なのでコードが長いこと以外は特に何も気になりませんね。
ある程度上級者になってくるとこっちの方がカスタマイズ性が高くて便利そうだと感じました。
おわりに
ということで今回はPytorchデビューということでMNIST画像で画像分類を行うモデルを作ってみました。
今後はPytorchでのネタも増やしていこうと思います。
このブログでは、このようなAIスキルを多数紹介しています。
ぜひ他のページもご覧ください。
それではまた!


コメント