

このページでは、AIの教師あり学習で使用される入力データ(input)と目標データ(output)を対応関係を維持した状態でシャッフルする方法をご紹介していきます。
学習前処理としてぜひご活用ください。
それではさっそくやっていきます。
※今回紹介するスキルは以前紹介した以下の記事を参考に作成しております。
基礎スキルはこちらで解説していますので、興味があればこちらもぜひご覧ください。
使用するデータサンプルデータの紹介
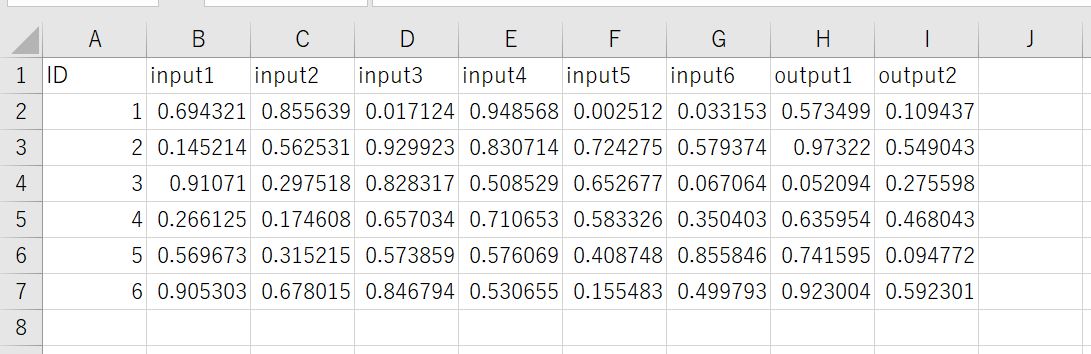
今回は以下のデータを使用していきます。
6つの入力データと2つの目標データがあるcsvファイルを使用します。
※ID数が非常に少ないですが、今回はシャッフル前後の結果がわかりやすくなるようにあえて少なくしています。
以降で紹介するサンプルコードは、
①このcsvファイルを読み込む
②入力データと目標データに分割する
③入力データと目標データの対応関係を維持した状態でシャッフルする
という流れを実行してみようと思います。
教師データをシャッフルするサンプルコード
それでは先ほど紹介した内容を実行できるサンプルコードを紹介します。
※使用するcsvファイルがプログラム実行フォルダにあることを想定して書いています。
import pandas as pd
import numpy as np
import random
data_file_name='training_data.csv'
data=pd.read_csv(data_file_name,index_col=0).values
#inputとoutputに分ける
inputdata=data[:,:6]
outputdata=data[:,-2:]
print('input_before_shuffle')
print(inputdata)
print('output_before_shuffle')
print(outputdata)
#inputとoutputの対応関係を維持したままシャッフル
num_data=len(inputdata)
shaffle_list=random.sample(range(0,num_data),num_data)
inputdata=inputdata[shaffle_list]
outputdata=outputdata[shaffle_list]
print('input_after_shuffle')
print(inputdata)
print('output_after_shuffle')
print(outputdata)
サンプルコードの実行結果
それでは先ほどのコードの実行結果を確認してみましょう。
まずはシャッフル前の入力データ(input)と目標データ(output)を表示した結果です。
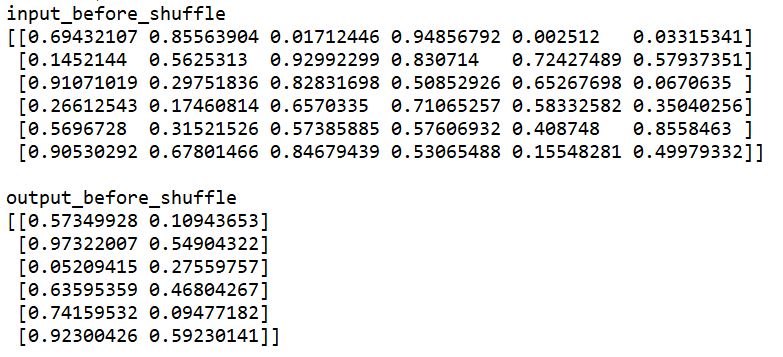
先ほど紹介した生のcsvファイルが以下ですので、問題なく読み込み⇒入力データ(input)と目標データ(output)への分割ができていることがわかります。
次はシャッフル後のデータを表示した結果です。
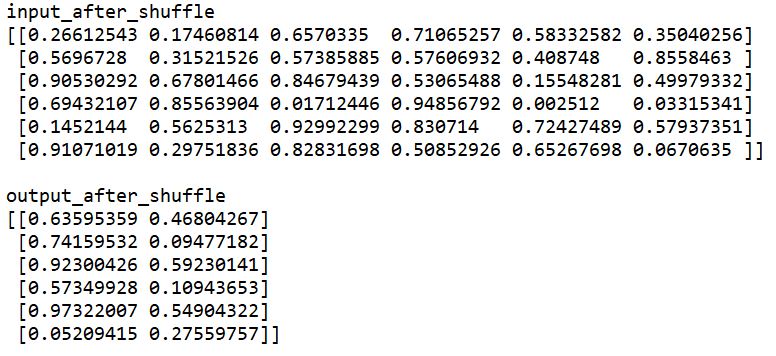
もともと1行目にあったデータが4行目に移動したり、もともと6行目にあったデータが3行目に移動したりと、問題なくシャッフルできていそうですね。
おわりに
というわけで今回はAIの教師あり学習で使用される入力データ(input)と目標データ(output)を対応関係を維持した状態でシャッフルする方法をご紹介しました。
データ前処理の際などにぜひご活用ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント