

こんにちは、ヒガシです。
このページでは、単語をベクトルに変換するモデルの代表格であるWord2Vecモデルの使い方解説を行います。
非常に簡単ですし、おもしろいのでぜひ一緒にやってみましょう!
gensimをインストールする
Word2Vecモデルを使うためには、まずはじめにgensimをインストールしましょう。
インストールする際はバージョン3.8.1を指定すると良いみたいです。
そもそもgensimとは何かというと今回扱うWord2Vecモデルのように「使えれば便利だけど自分だけで使えるようにするのは敷居が高い」みたいなモデルを非常に簡単に使えるようにしてくれるライブラリだと思えばOKです。
今回使うWord2Vecモデル以外もgensimを使えば簡単に使えるようになります。
すでにgensimがインストールされている方も
でバージョンを確認しておきましょう。
どうやらWord2Vecモデルはバージョンが新しすぎるとうまく動作しないみたいです。
Word2Vecモデルをローカルにダウンロードする
次は以下のページにいって日本語に対して学習済みのWord2Vecモデルをダウンロードします。
下の方にあるjapanese(w)をクリックすればダウンロードできるはずです。
ダウンロードしたzipファイルを解凍し、これからプログラムを実行するフォルダに置いておきましょう。
Word2Vecモデルで日本語をベクトル化する
それでは事前準備はここまでにして実際にWord2Vecモデルをつかってみましょう。
まずは「今日」という単語をベクトル化してみます。
import gensim
import numpy as np
model = gensim.models.Word2Vec.load('data/ja.bin')
a = model["今日"]
print(a)
以下が出力されました。(実際はもっと下まであります。)
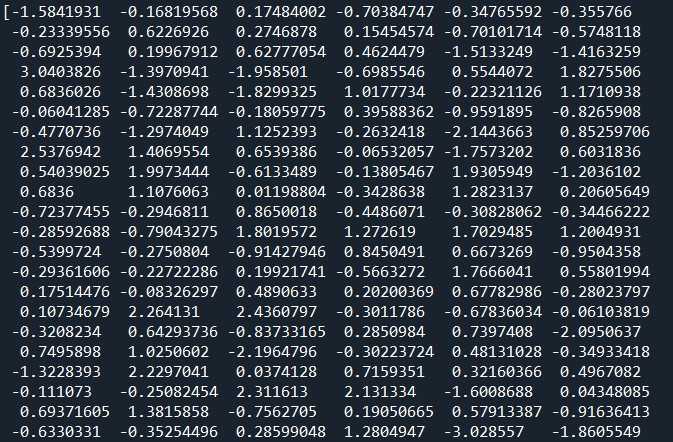
a.shapeで次数を確認したところ300次元ありました。
どんな単語をいれても300次元のベクトル化して返してくれるみたいですね。
2つの単語ベクトルの内積を計算してみる
次は先ほどの手順で作成した2つのベクトルに対して、内積を計算してみます。
内積というのは、ベクトルどうしの類似度を計算できるものです。
似たような2つの単語ベクトルの内積が高くなり、似てない2つの単語の内積が小さくなるのかを確認してみましょう。
以下がそのコードです。
import gensim
import numpy as np
model = gensim.models.Word2Vec.load('data/ja.bin')
a = model["今日"]
b = model["明日"]
inner_product = np.dot(a, b)
print("今日 明日 の内積")
print(inner_product)
a = model["今日"]
b = model["東京"]
inner_product = np.dot(a, b)
print("今日 東京 の内積")
print(inner_product)
こいつを実行すると以下の結果が出力されました。
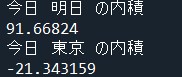
似た単語である今日と明日の内積は大きく、あまり関係のない今日と東京の内積は小さくなっていますね。
イメージ通りの結果です。
おわりに
ということで今回はWord2Vecモデルを使って日本語の単語をベクトルに変換する方法をご紹介しました。
こいつを使えば色々な自然言語処理に応用できそうですね。
このブログでは、このようなAIスキルを多数紹介しています。
ぜひ他のページもご覧ください。
それではまた!


コメント