

こんにちは、ヒガシです。
今回は以前紹介した画像分類AIモデルを活用し、学習データの数と予測精度の関係を調査していきたいと思います。
具体的にやっていくこととしては、以下に示すような適当な丸、三角、四角の画像を1000枚準備し、最後の200枚をテスト用として固定し、残った800枚のうちから学習に使用するデータの数を100,200,300・・・,800と変えながら画像分類AIモデルを学習させていき、データの増強に対する予測精度の変化を確認していきます。
AIの学習データがどのくらい必要なのかは適用対象によっても大きく変わってくると思いますし、データが多ければ多いほど良いのはわかっていますが、どんな感度なのか調査したことがなかったので実際に検証してみようと思います。
それではさっそくやっていきましょう!
※KerasのCNNモデルを使って実演していきます。
サンプル画像データを大量に生成しておく
画像データがなければ始まりませんので、まずは画像データを1000枚生成します。
以下がそのサンプルコードです。
これを実行すれば、指定のフォルダにランダムに丸、三角、四角の画像が生成されます。
また、sub_info.csvというデータも生成され、その中には正解となるラベルが格納されています。
データ数をもっと増やしたい場合はnum_pic=1000のところを増やせばOKです。
#ライブラリインポート
from PIL import Image
import cv2
import numpy as np
import pandas as pd
import os
import random
import glob
import matplotlib.pyplot as plt
base_dir='/content/drive/MyDrive/CNN_sample'
os.makedirs(base_dir, exist_ok=True)
#作成する画像の枚数
num_pic=1000
#画像のサイズ
h=64
w=64
sub_info=[]
for i in range(num_pic):
img=np.zeros((h,w),np.uint8)
x1=random.randint(20,w-30)
y1=random.randint(20,h-30)
x2=random.randint(30,w-20)
y2=random.randint(30,h-20)
size=random.randint(5,12)
b=random.randint(150,255)
thickness=random.randint(1,3)
angle=random.randint(0,359)
rnd=random.randint(0,2)
x=int((x1+x2)/2)
y=int((y1+y2)/2)
if rnd==0:
cv2.circle(img,(x,y),radius=size,color=b,thickness=thickness)
elif rnd==1:
cv2.rectangle(img,(x1,y1),(x2,y2),color=b,thickness=thickness)
else:
cv2.drawMarker(img,(x,y),b,markerType=cv2.MARKER_TRIANGLE_UP,markerSize=size,thickness=thickness)
ROT=cv2.getRotationMatrix2D(center=(int(w/2),int(h/2)),angle=angle,scale=1)
img=cv2.warpAffine(img,ROT,dsize=(w,h))
sub_info.append([x,y,size,b,thickness,angle,rnd])
cv2.imwrite(base_dir+'/sample_data_'+str(i).zfill(3)+'.jpg', img)
np.savetxt(base_dir+'/sub_info.csv', sub_info, delimiter=",")
AIが読み込める形にデータを加工する
次に先ほど生成したデータをAIが読み込める配列の形に変更します。
これでXdata, Ydataの中に入力となる画像のデータ、出力となる分類結果が格納されています。
pics=glob.glob(base_dir+'/sample_data*.jpg')
sub_info=pd.read_csv(base_dir+'/sub_info.csv', header=None).values
#入出力データを入れる箱を準備
Xdata=[]
Ydata=[]
i=0
for pic in pics:
#画像を1枚読み込む
img = Image.open(pic)
#輝度を正規化する
img=np.array(img)/255
#読み込んだ画像を入力の箱に加える
Xdata.append(img)
#画像に対応する出力データ(分類結果を表すデータ)を作成する
#円だったら(1,0,0)四角なら(0,1,0),三角なら(0,0,1)
Y=np.zeros(3,np.uint8)
Y[int(sub_info[i,-1])]=1
#出力データの箱に入れる
Ydata.append(Y)
i+=1
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
データ数を変更しながらCNNモデルを学習させる
それではここからが本題です。
先ほど構築したデータを評価用200個、学習用を任意の数に分割しながら連続でモデルを学習させていってみます。
今回は学習用データを100,200,300,400,500,600,700,800個と振って学習させていってみます。
以下がそのコードです。
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D,Dropout, Flatten,concatenate, BatchNormalization
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import keras
history_list=[]
num_data_list=[100,200,300,400,500,600,700,800]
for num in num_data_list:
#データを学習用、評価用に分割する
Xdata_train=np.copy(Xdata[:int(num)])
Xdata_valid=np.copy(Xdata[-int(200):])
Ydata_train=np.copy(Ydata[:int(num)])
Ydata_valid=np.copy(Ydata[-int(200):])
#モデルを定義する
input = Input(shape=(64,64,1))
model = Conv2D(32, (3, 3), padding='same', activation='relu')(input)
model = BatchNormalization()(model)
model = MaxPooling2D((2, 2))(model)
model = Conv2D(32, (3, 3), activation='relu')(model)
model = BatchNormalization()(model)
model = MaxPooling2D((2, 2))(model)
model = Conv2D(16, (3, 3), activation='relu')(model)
model = BatchNormalization()(model)
model = MaxPooling2D((2, 2))(model)
model = Conv2D(8, (3, 3), activation='relu')(model)
model = BatchNormalization()(model)
model = MaxPooling2D((2, 2))(model)
model = Flatten()(model)
model = Dense(32, activation='relu')(model)
model = Dropout(0.5)(model)
model = Dense(3, activation='softmax')(model)
model = Model(inputs=input, outputs=model)
model.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.001),metrics=['accuracy'])
model.summary()
#学習させる
history=model.fit(Xdata_train,Ydata_train,batch_size=16,epochs=100,validation_data=(Xdata_valid,Ydata_valid))
#学習履歴を保存しておく
history_list.append(history)
keras.backend.clear_session()
学習履歴は変数history_listに格納されています。
学習データ数違いでの精度変化を確認してみる
最後に先ほどのプログラムを実行することで得られた各学習データ数での学習結果をみてみましょう。
以下がそのコードです。
data=[]
#各学習データでの学習結果をグラフ化する処理
for i in range(len(num_data_list)):
plt.plot(history_list[i].history['val_accuracy'],label='num_data='+str(num_data_list[i]))
plt.legend(loc='lower right',fontsize=7)
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
data.append(np.average(history_list[i].history['val_accuracy'][-20:]))
plt.savefig(base_dir+'/num='+str(num)+'.jpg')
plt.show()
plt.scatter(num_data_list,data)
plt.ylabel('Accuracy')
plt.xlabel('Number of data')
plt.title('Average Accuracy of Epoch 80-100')
plt.show()
まずは学習データ違いでのエポック数に対する予測精度の履歴を見てみましょう。
(これらは学習に使っていない検証用データ200個に対する予測精度です。)
以下がその結果です。
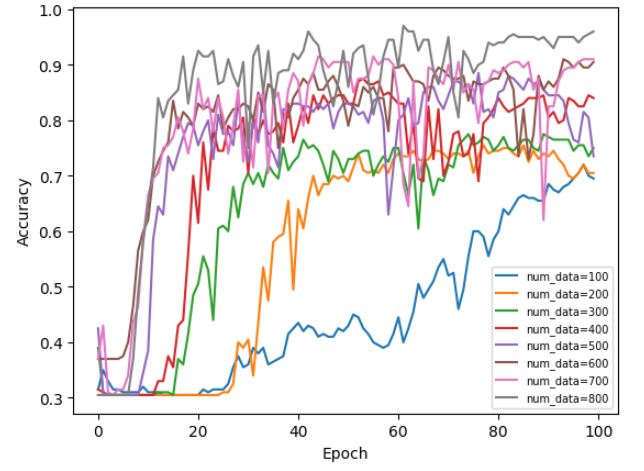
予想通りではありますが、学習用データが多い方が予測精度が高くなる傾向が見て取れますね。
さらに精度が上昇してくるまでに要するエポック数も減っていっているように見えますね。
次に以下が80~100エポック間の平均正解率と学習データ数の関係を見てみましょう。
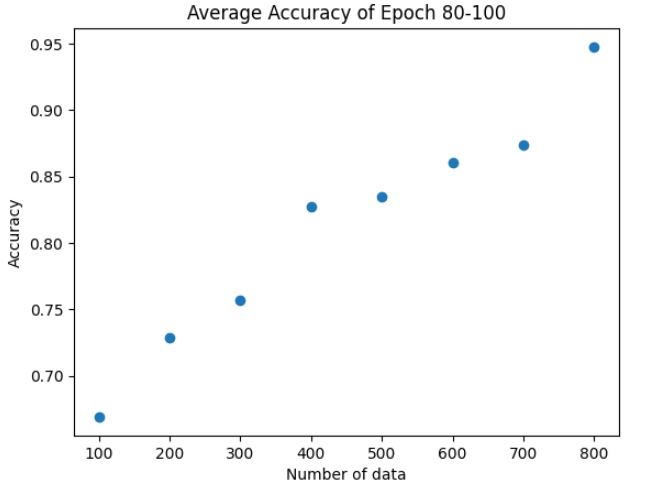
きれいに右肩あがりの傾向をしていますね。
1000個くらいあれば検証用データでも正解率100%にできそうですね。
まとめ
ということで今回は画像分類CNNモデルに対して、学習データ数と予測精度の関係を調査してみました。
ザ・予想通りの結果でしたね。
逆に何個まで削減したらガクッと精度がおちるとかも見てみたいですね。
次回検証してみようと思います。
それではまた!


コメント