

こんにちは、ヒガシです!
今回は作成したAIモデルの出力が、各入力に対してどれくらい寄与しているかを分析できるshapという技術の使い方をご紹介していきます。
※Kerasで自作した簡単なモデルに対して実演していきます。
先日私が参加した学会でもshapは多く使われており、今非常に注目されている技術です。
ぜひ使い方をマスターしておきましょう!
それではさっそくやっていきましょう!
サンプルデータを構築する
モデルを作って実際にshapで分析するという一連の流れを実施していこうと思いますが、複雑なデータを使ってモデルを構築した場合、shapを使って出てきた結果が本当にあっているのかよくわからいと思います。
ですので今回は簡単な数式を使ってデータを自作し、そのデータでモデル構築⇒shap分析という流れで進めようと思います。
というわけでまずはデータの構築です。
今回は以下のようにエクセルで適当にデータセットを作成しました。
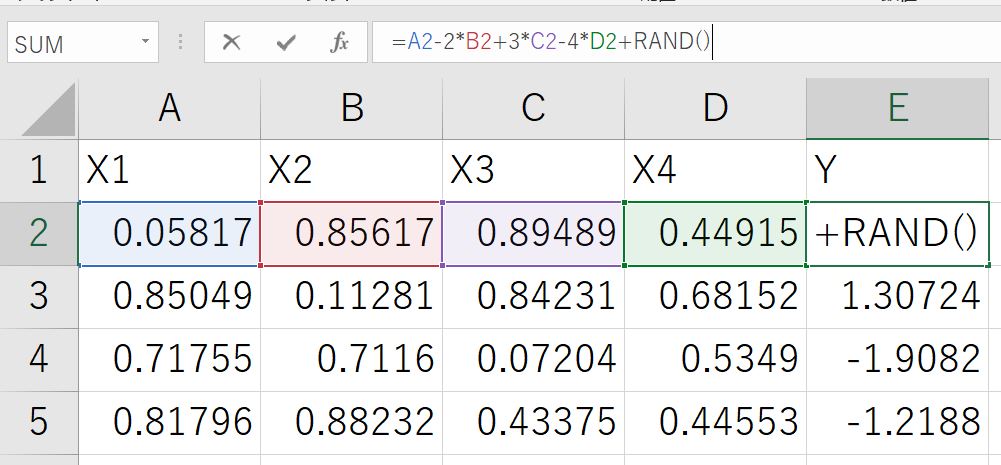
こんな感じで
Y=X1-2*X2+3*X3-4*X4+乱数
という数式を作成し、似たようなデータを100個作成しています。
今回はこのYをX1~X4までを入力として予測していくモデルを構築するわけですが、当然ながらYに与える寄与度はX1が1, X2が2, X3が3, X4が4になりますね。
この寄与度がしっかりとshapで抽出できるかを、以降の項目で検証していきましょう。
なお、このデータをsample_data_shap.csvという名前で保存していある状態で以降の話は進めていきます。
KerasでAIモデルを構築する
それでは先ほど構築したデータを使って実際にモデルを構築していきましょう。
今回はKerasのSequentialモデルを使って構築していきます。
ここは本題とはずれますのでコードだけさらっとご紹介します。
#ライブラリ読み込み
from keras.models import Sequential
from keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
#データ読み込み
data=pd.read_csv('sample_data_shap.csv').values
Xdata=data[:,:-1]
Ydata=data[:,-1]
#モデル構築
model=Sequential()
model.add(Dense(100,input_shape=(4,)))
model.add(Dense(100))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.0001), metrics=['mae'])
model.summary()
history =model.fit(Xdata, Ydata, validation_split=0.2, epochs=200, batch_size=16)
# 損失のplot
plt.plot(history.history['loss'], marker='.', label='loss')
plt.plot(history.history['val_loss'], marker='.', label='val_loss')
plt.title('model loss')
plt.grid()
plt.ylim(0,2)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='best')
plt.show()
こいつを実行すると以下の結果が得られました。
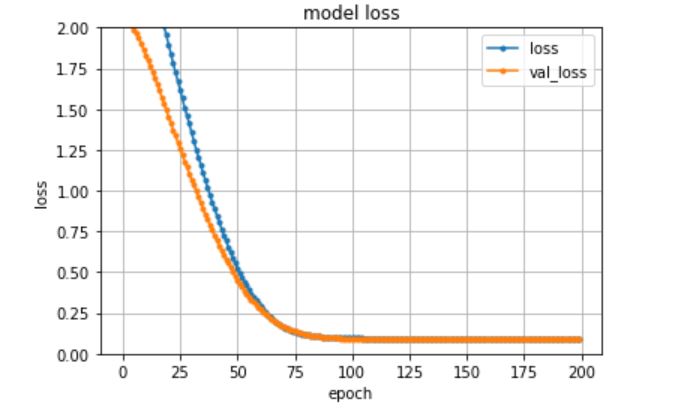
しっかりとロスが減ってますね。
学習は問題なく実行できました。
shapで寄与度を分析してみる
前置きが長くなりましたが、ここからが本題です。
それでは先ほど作成したモデルをshapで寄与度分析してみましょう。
以下がそのコードです。
※データ数が多いと非常に時間がかかりますのでご注意ください。
import shap
shap.initjs()
Xname=['X1','X2','X3','X4']
explainer = shap.KernelExplainer(model.predict, Xdata)
shap_values=explainer.shap_values(Xdata)
shap.summary_plot(shap_values, Xdata, feature_names=Xname, plot_type='bar', class_names=['Y'])
こいつを実行すると以下の結果が得られました。
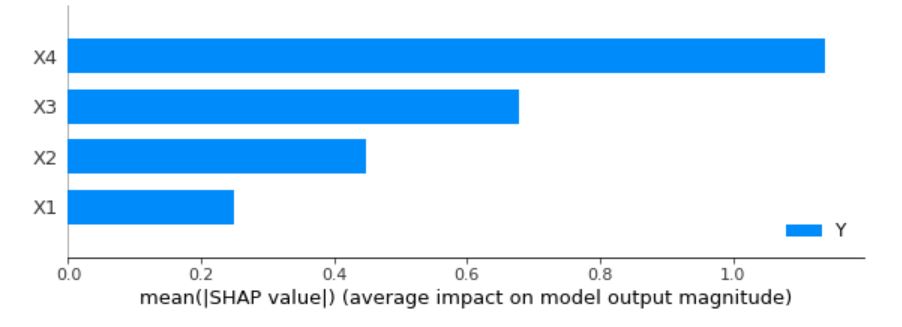
しっかりとX1の寄与度が小さく、X4に向かうにしたがって寄与度が大きくなっていますね。
※厳密には等間隔に寄与度が大きくなってほしいところですが、データ形成の際に乱数も含めていますのでモデルの学習精度の問題でしょうね。
寄与度の正負まで含めてshap分析したい場合
先ほど紹介した例だと寄与度はしっかりと分析できていましたが、Yの出力結果を大きくする側に寄与するのか小さくする側に寄与するのかがよくわかりませんでしたよね。
今回構築したデータは
Y=X1-2*X2+3*X3-4*X4+乱数
という数式で構築していますので、X1, X3はプラスの寄与度、X2, X4はマイナスの寄与度を持っているはずです。
次はこれらの正負まで含めて寄与度分析してみましょう。
その方法は以下の通りです。
import shap
shap.initjs()
Xname=['X1','X2','X3','X4']
explainer = shap.KernelExplainer(model.predict, Xdata)
shap_values=explainer.shap_values(Xdata)
shap.summary_plot(shap_values[0], Xdata, feature_names=Xname, plot_type='dot', class_names=['Y'])
こいつを実行すると以下の結果が得られました。
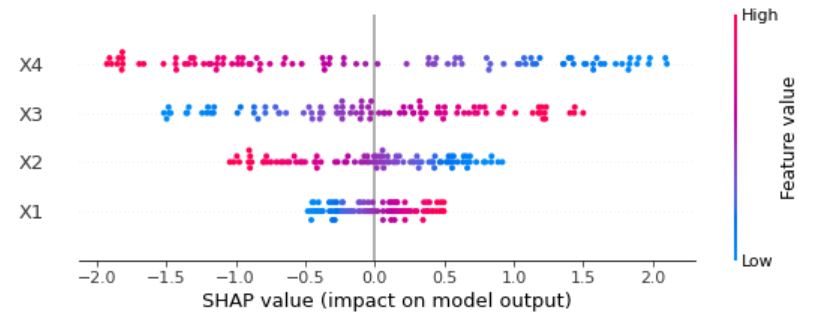
こいつを見るとX1,X3は0より右側が赤く、X2,X4が0より左側が赤くなっています。
これがそれぞれの入力がYの出力に対してプラスの寄与をするかマイナスの寄与をするかを表しています。
というわけでこの手法なら正負も含めて分析することができそうですね。
おわりに
というわけで今回は自作したKerasのモデルに対してshapという技術を使い、それぞれの入力の寄与度を分析する方法をご紹介しました。
AIモデルでブラックボックスというイメージが強いと思いますが、こういった手法もあるのでぜひモデルの解釈にご利用ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント