

こんにちは、ヒガシです。
このページでは、AI分野において時系列データを予測する際によく用いられるLSTMモデルに対して、複数の入力、複数の出力を持つデータを使用する方法をご紹介していきます。
LSTMのサンプルコードはネット上に多々落ちていると思いますが、入力が複数、出力も複数というパターンはそれほど多くないので今回その方法をじっくり解説しながらご紹介していきます。
今回紹介する内容は、各入出力に対する1次元配列を準備するだけで作成できるようになっています。
ぜひモデル構築の際にご活用ください。
それではさっそくやっていきましょう!
※今回はKerasのLSTMに入れることを前提に書いていきます。Pytorchでも同じように作ってよいかはわかりませんのでご了承ください。
事前準備:LSTM用の時系列データを準備する
時系列データがなければ話になりませんので、まずはその作成から始めましょう。
今回はデータの作り方の解説ですので、入力データとしてSIN波, COS波を複数(計4つ)使用し、出力データとしてそれらの合成波(計2つ)を使用したいと思います。
以下がそのサンプルコードです。
import numpy as np
xdeg=1440
x = np.arange(0,xdeg+1)
sinx=np.sin(2*np.pi*x/360)+np.random.rand(len(x))/20
sin2x=np.sin(2*2*np.pi*x/360)+np.random.rand(len(x))/20
cosx=np.cos(2*np.pi*x/360)+np.random.rand(len(x))/20
cos2x=np.cos(2*2*np.pi*x/360)+np.random.rand(len(x))/20今回はx=0~1440degまでのsin(x),sin(2x),cos(x),cos(2x)の4つの時系列データを用意しました。
変数sinxの中身を確認してみましょう。

こんな感じで1次元配列になっています。
以降で紹介するサンプルコードは基本的にはすべてのデータが1次元配列になっていることを前提に書いていきます。
あなたが自前のデータを使用して実行する際は、まずは各データを1次元配列に直してから使用するようにしてください。
今回はそれぞれのデータから以下のように入力データ4つ、出力データ2つを作成しています。
X1=sinx
X2=cosx
X3=sin2x
X4=cos2x
Y1=X1+X2+X3+X4
Y2=X1-X2+X3-X4
もし入力、出力のデータ数を変更したい場合は、ここの変数を増やすなり減らすなりして対応してください。
念のためグラフ化してデータを確認しておきましょう。
以下のプログラムでデータをグラフ化してみます。
import matplotlib.pyplot as plt
plt.plot(range(0, len(x)), X1, color="b", label="X1")
plt.plot(range(0, len(x)), X2, color="r", label="X2")
plt.plot(range(0, len(x)), X3, color="g", label="X3")
plt.plot(range(0, len(x)), X4, color="y", label="4")
plt.legend()
plt.show()
plt.plot(range(0, len(x)), Y1, color="b", label="Y1")
plt.plot(range(0, len(x)), Y2, color="r", label="Y2")
plt.legend()
plt.show()
こいつを実行すると以下の2つのグラフが出力されました。
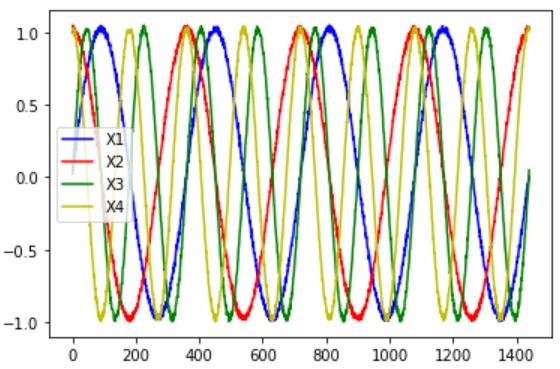
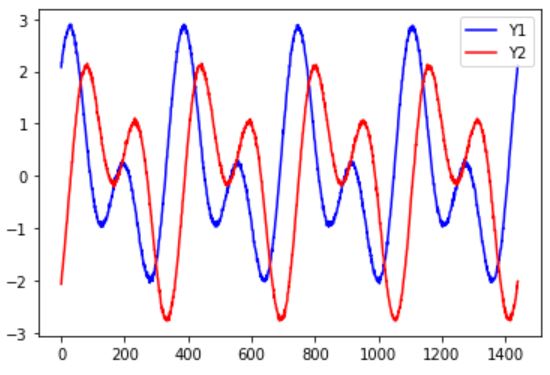
上のグラフ4本の過去複数時刻分のデータを入力として、下の2本の次の時刻のデータを予測するという流れですね。
事前準備が終わったところで、次はLSTMモデルにインプットできるようにデータの前処理をおこなっていきましょう!
LSTMモデル用に複数の時系列入出力データを前処理する方法
それでは先ほど作成した4つの入力データ、2つの出力データをLSTMモデル用に前処理を行っていきましょう!
先ほども説明しましたが、入力は過去数時刻分の時系列データとし、出力は次の1時刻でのデータとしています。
X_list=[X1,X2,X3,X4]
Y_list=[Y1,Y2]
Xdata=[]
Ydata=[]
look_back=5
for i in range(len(x)-look_back):
Xtimedata=[]
for j in range(len(X_list)):
Xtimedata.append(X_list[j][i:i+look_back])
Xtimedata=np.array(Xtimedata)
Xtimedata=Xtimedata.transpose()
Xdata.append(Xtimedata)
Ytimedata=[]
for j in range(len(Y_list)):
Ytimedata.append(Y_list[j][i+look_back])
Ydata.append(Ytimedata)
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
これでもうKerasのLSTMに入れることはできます。
※Xdataが入力データ、Ydataが出力データです。
作成したデータをLSTMモデルに入れてみる
それでは先ほど作成した複数の入出力を持つデータをLSTMモデルに入れてみましょう。
以下がそのサンプルコードです。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import Adam
Xdim=Xdata.shape[2]
Ydim=Ydata.shape[1]
validation_split_rate=0.2
model = Sequential()
model.add(LSTM(4, input_shape=(look_back,Xdim)))
model.add(Dense(Ydim))
model.compile(loss="mean_squared_error", optimizer=Adam(lr=0.001))
model.summary()
history=model.fit(Xdata,Ydata,batch_size=16,epochs=100,validation_split=validation_split_rate)
こんな感じで問題なく学習がスタートできました。

学習履歴、精度を可視化もしてみる
ここまでくるともう本題とはずれていますが、念のため学習がちゃんと進んだか見てみましょう。
まずは損失の減り具合を見てみましょう。
以下のコードで確認します。
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()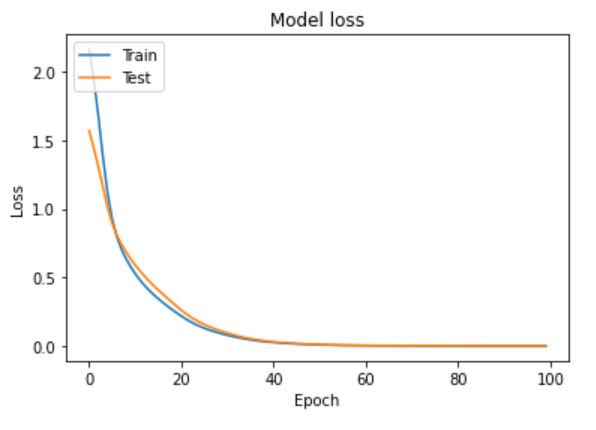
問題なく学習が進んでいそうですね。
次は精度の確認です。
以下のコードで確認してみます。
Xdata_validation=Xdata[-int(len(Xdata)*(validation_split_rate)):]
Ydata_validation=Ydata[-int(len(Ydata)*(validation_split_rate)):]
Predictdata = model.predict(Xdata_validation)
plt.plot(range(0, len(Predictdata)),Predictdata[:,0], color="b", label="predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,0], color="r", label="row_data")
plt.legend()
plt.show()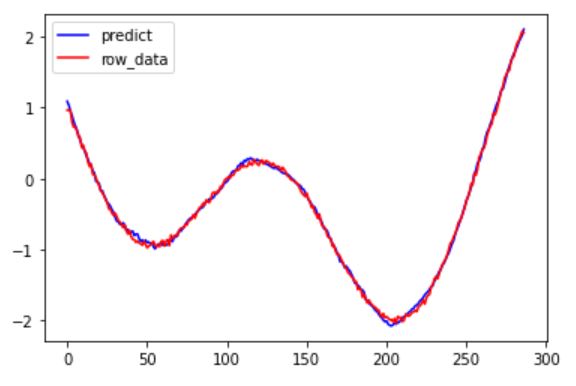
簡単な例なのでかなり精度よく予測できていますね。
複数の入出力を持つLSTMの全体サンプルプログラム
それでは最後にここまで紹介してきたプログラムの全体像を書いておきます。
#ライブラリインポート
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
#データ準備
xdeg=1440
x = np.arange(0,xdeg+1)
sinx=np.sin(2*np.pi*x/360)+np.random.rand(len(x))/20
sin2x=np.sin(2*2*np.pi*x/360)+np.random.rand(len(x))/20
cosx=np.cos(2*np.pi*x/360)+np.random.rand(len(x))/20
cos2x=np.cos(2*2*np.pi*x/360)+np.random.rand(len(x))/20
X1=sinx
X2=cosx
X3=sin2x
X4=cos2x
Y1=X1+X2+X3+X4
Y2=X1-X2+X3-X4
#入力データの可視化
plt.plot(range(0, len(x)), X1, color="b", label="X1")
plt.plot(range(0, len(x)), X2, color="r", label="X2")
plt.plot(range(0, len(x)), X3, color="g", label="X3")
plt.plot(range(0, len(x)), X4, color="y", label="X4")
plt.legend()
plt.show()
plt.plot(range(0, len(x)), Y1, color="b", label="Y1")
plt.plot(range(0, len(x)), Y2, color="r", label="Y2")
plt.legend()
plt.show()
#LSTM用にデータの前処理
X_list=[X1,X2,X3,X4]
Y_list=[Y1,Y2]
Xdata=[]
Ydata=[]
look_back=5
for i in range(len(x)-look_back):
Xtimedata=[]
for j in range(len(X_list)):
Xtimedata.append(X_list[j][i:i+look_back])
Xtimedata=np.array(Xtimedata)
Xtimedata=Xtimedata.transpose()
Xdata.append(Xtimedata)
Ytimedata=[]
for j in range(len(Y_list)):
Ytimedata.append(Y_list[j][i+look_back])
Ydata.append(Ytimedata)
Xdata=np.array(Xdata)
Ydata=np.array(Ydata)
#LSTMモデルの構築⇒学習開始
Xdim=Xdata.shape[2]
Ydim=Ydata.shape[1]
validation_split_rate=0.2
model = Sequential()
model.add(LSTM(4, input_shape=(look_back,Xdim)))
model.add(Dense(Ydim))
model.compile(loss="mean_squared_error", optimizer=Adam(lr=0.001))
model.summary()
history=model.fit(Xdata,Ydata,batch_size=16,epochs=100,validation_split=validation_split_rate)
#学習結果の可視化
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
#精度検証
Xdata_validation=Xdata[-int(len(Xdata)*(validation_split_rate)):]
Ydata_validation=Ydata[-int(len(Ydata)*(validation_split_rate)):]
Predictdata = model.predict(Xdata_validation)
plt.plot(range(0, len(Predictdata)),Predictdata[:,0], color="b", label="predict")
plt.plot(range(0, len(Ydata_validation)),Ydata_validation[:,0], color="r", label="row_data")
plt.legend()
plt.show()
おわりに
というわけで今回は複数の入出力データを持つLSTMモデルの作成⇒精度検証をKerasを使ってやってみました。
データ分析の際などにぜひご活用ください。
このように、私のブログでは様々なAIスキルをご紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント