

こんにちは、ヒガシです。
今回は連続値を扱える強化学習アルゴリズムであるDDPG(Deep Deterministic Policy Gradient)を難しい数式抜きにざっくりと画像と言葉で解説していきます。
DDPGについて詳細に解説してくれているサイトは多々ありますが、私のようなメーカーエンジニアにとっては、理論を深く詳細に把握するよりも、概要だけ把握して素早く適用する方が有益だったりしますので、私と同じように「最低限のイメージだけ固めたい」という人向けに今回は書いていきます。
他のサイトでは難しい数式で解説しているところを、私なりのざっくり解説をしていきます。ですので概要はすでにわかっている&詳細理論を学びたい人にとっては全く参考になりませんので、その点はご了承ください。
ただし、State(状態)とかAction(行動)、Reward(報酬)といった強化学習で使われる用語の最低限の知識をあることを前提に書いていきますので、そのあたりも全くしらないという方はまずは以下の記事等を参考に基礎勉強を進めてから読むことをオススメします。
それではさっそくやっていきましょう!
DDPGモデルの概要
まずはDDPGのモデル概要からです。
以下がDDPGモデルの概要図を表したものです。
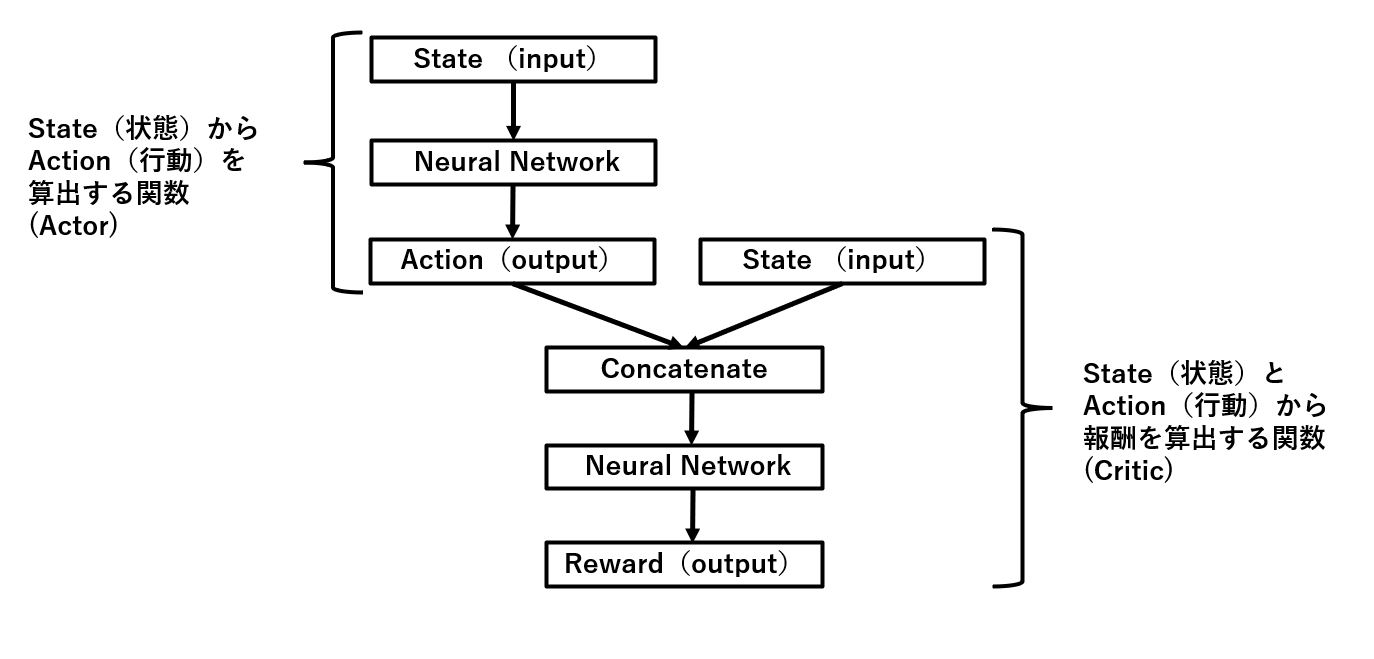
Stateを入力するとActionを出力してくれる関数(Actor)と、StateとActorが出力したActionの2つを入力としてRewardを出力する関数(Critic)の2つの関数で構成されています。
Critic側のネットワークの学習方法
まずはStateとActorが出力したActionの2つを入力としてRewardを出力する関数側のニューラルネットワークがどのように学習されていくのかを解説していきます。
まず、強化学習でやっていることをざっくりとおさらいしておきましょう。
強化学習では、ある状態において、ある行動をした際に、その時の状況に応じた報酬がもらえるんでしたよね。
つまり、入力が(状態,行動)だったときの出力(報酬)がセットで存在しているということです。
これは一般的な教師あり学習で用いられるデータ構造と全く同じです。
というわけで、Critic側のニューラルネットワークは、まずはベースとして教師あり学習と同じ要領で学習を進めるということです。
しかしながら、強化学習の特性上、それをやると不安定になるので、実際は以下のようにしています。
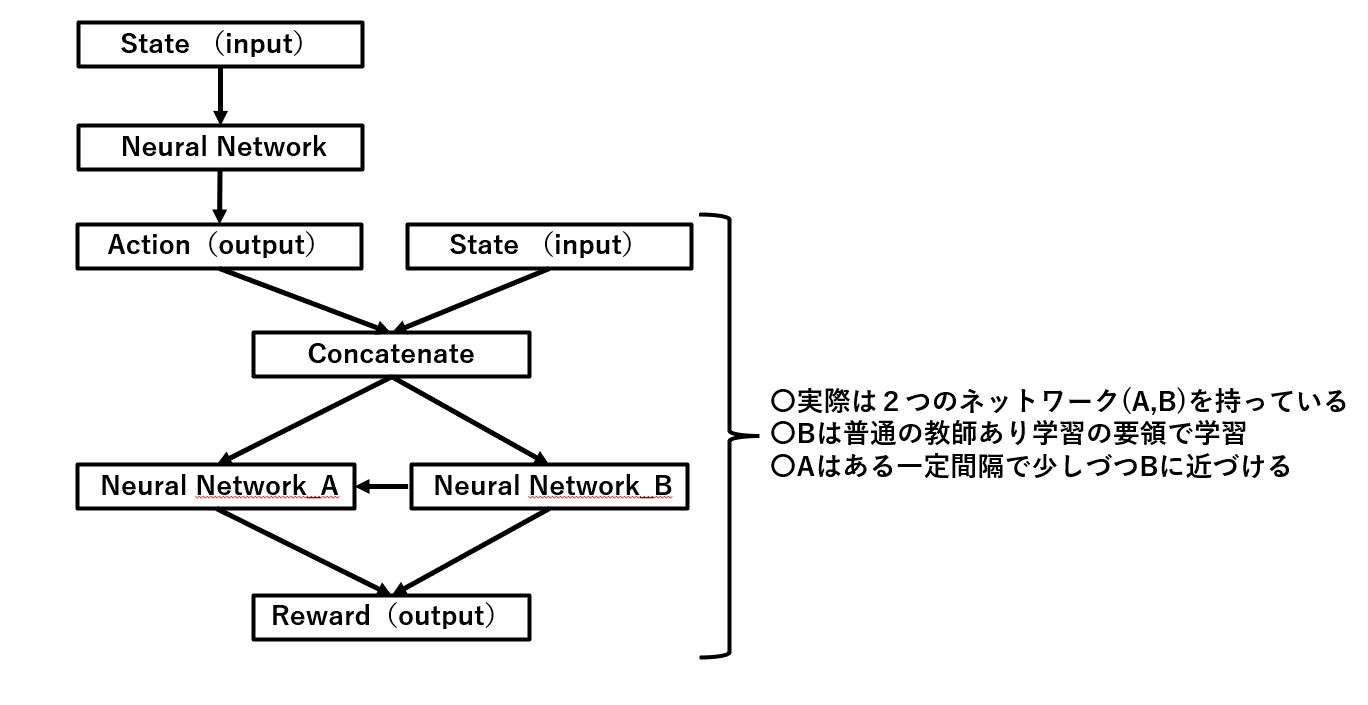
こんな感じで同じような役割をもつネットワークを2つ構成し、1つ目は通常の教師あり学習の要領で学習を進める、2つ目のネットワークは1つ目のネットワークの重みに徐々に近づけていく形で調整していく、という流れです。
専門的に言うとSoft-Targetといかいうみたいです。
こうすることで安定性を保ちながら学習を進めることが可能になるわけですね。
いずれにせよ、このような学習を大量の試行錯誤によって得られたデータに対して繰り返し実行していくことによって、ある状態において、ある行動をしたときの報酬を予測することができる関数ができあがるというわけです。
Actor側のネットワークの学習方法
次はActor側のネットワークの学習方法です。
こっちは正直数学的に理解しようとすると結構難しいです。
なので本当にざっくりと言葉だけで説明します。
まずは最初の概要図をもう一度見てみましょう。
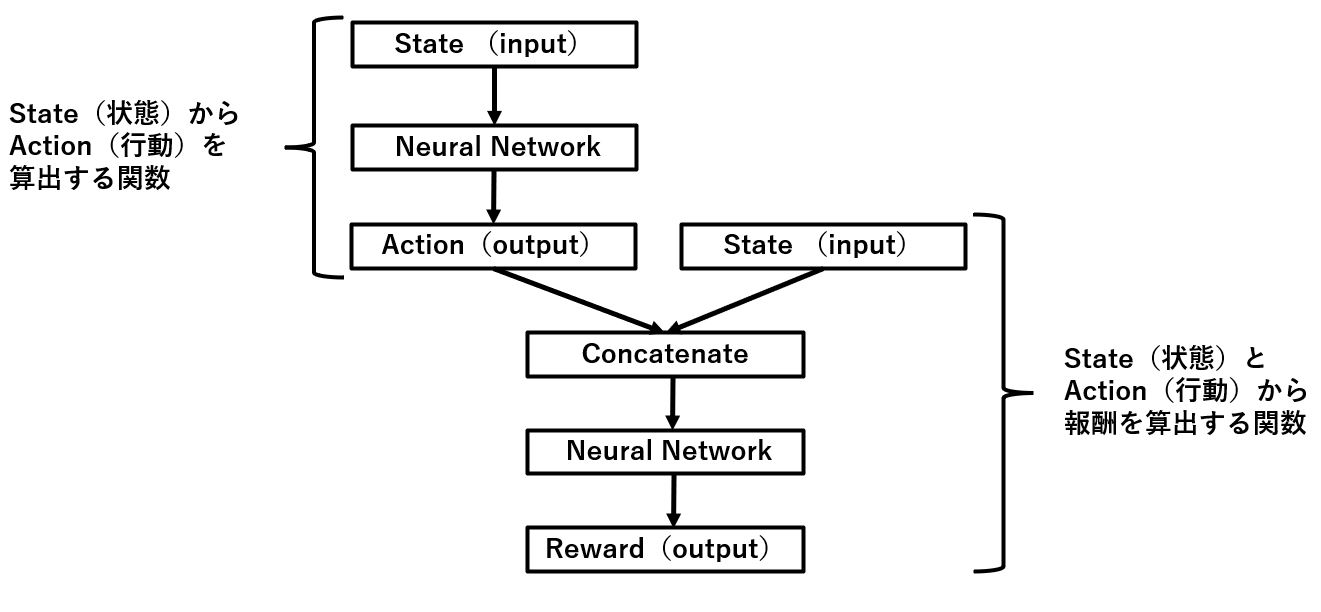
Actor側のニューラルネットワークはStateを入力としてActionを出すだけですね。
では、このActionはどうあればよいのでしょうか?
答えは、後ろに繋がっているCritic関数にActionを入れた際に、出力される報酬が最大になってくれるActionを出せばよいんです。
ここで、Critic側の関数は先ほど紹介した手順で学習することで、ある程度正確な報酬が出せるという前提で考えてみましょう。
つまりActor側からすれば、ある状態を入力にして何かしらのActionを出したら、Critic関数を通じて算出された報酬が出てくるという状況です。
逆に考えれば、どんなActionを出せばCritic関数を通じて出てくる報酬が最も大きくなるということもわかるわけですね。
だったらその最大報酬になるActionをどんな状況においても出せるようにActor側のニューラルネットワークを学習しておけばいいということです。
要は完璧に学習が終わった際には、どんなStateが入っても貰える報酬が最大になるようなActionが自動的に出てくるニューラルネットワーク(Actor)が完成しているわけです。
テスト時のDDPGモデルについて
ここまではDDPGモデルをどうやって学習させているのか?を中心に話をしてきましたが、次は学習が終わって実際にテストする際の挙動を考えてみましょう。
テストをする際は、
あるStateになりました⇒ActorモデルでActionを出す⇒Stateが更新される⇒新しいStateに対してまたActorモデルでActionを出す・・・を繰り返すだけですよね。
Actorモデルは常に報酬を最大化するようなActionを出してくれているはずですので、報酬を算出するためのCriticモデルは必要ありません。
もう一度全体像でおさらいすると以下の画像の左上のState⇒Actionを出す部分しか使っていないのです。
Actorが出したActionを環境側に渡してStateを更新してまたActorがActionを出す・・・を繰り返すだけですね。
おわりに
というわけで今回は連続値を扱える強化学習アルゴリズムであるDDPGの概要を数学に詳しくない人むけに言葉と画像で丁寧に説明してきました。
今後もAI系の記事を書いていこうと思いますので、興味があればぜひブックマークをお願いします。
〇合わせて読みたい!
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント