

この記事では、以下の画像のようにあるファイル名の中で使われている数字を抜き出して、プログラム上で使用する方法をご紹介していきます。
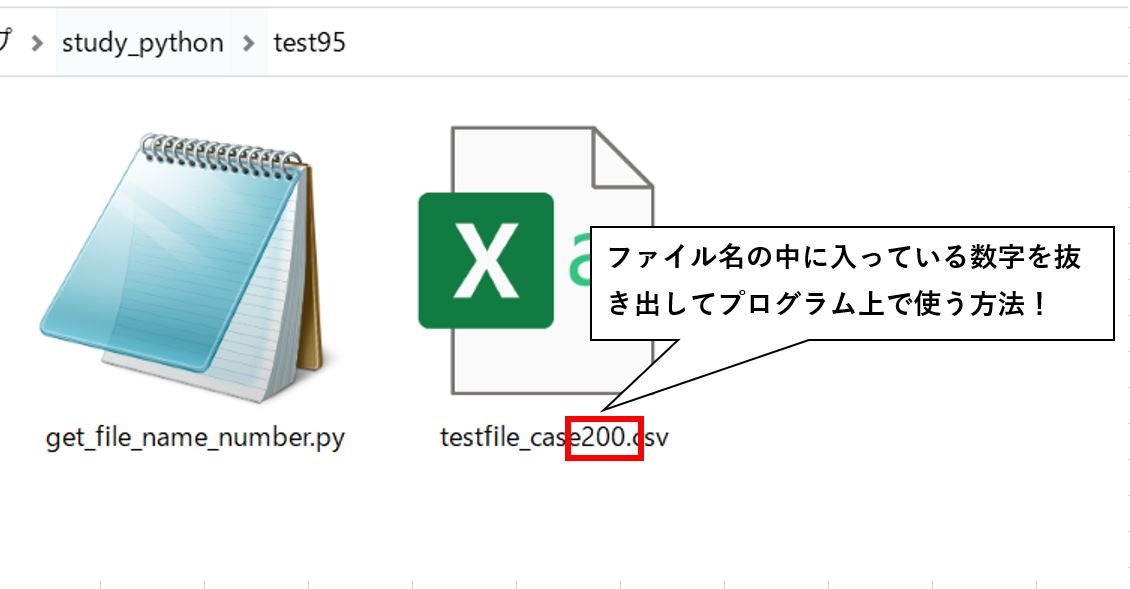
※今回のプログラムは、使用したい数字部分の桁数がわかっている(005なんかは使用可能です)&数字部分が存在する場所がわかっている場合にのみ有効です。
自動で数字部分を探索して取り出すことはできませんので、ご注意ください。
ファイル名から数字を抜き出し、別ファイルのその行数を参照する、といった場面で使えるスキルになっています。
それではやっていきましょう!
ファイル名中の数字を抜き出すサンプルコード
さっそくですが、以下が冒頭に紹介したような処理を実行してくれるサンプルコードです。
import glob
import numpy as np
file_name=glob.glob('*.csv')
print(file_name)
#まずはファイル名の文字列を取得
Nstr=len(file_name[0])
#ファイル名の文字列から数字の部分を抜き出す
num=file_name[0][Nstr-7:Nstr-4]
#この時点では文字列として扱われてるので整数型に変換
num=int(num)
#取得した数値を実際に使ってみる
test_array=np.zeros((num,num),np.uint8)
#問題なく使えているかの確認
print(test_array.shape)
各コードにコメントを付けておりますので、何をやっているかはわかりやすいはずです。
今回は文字列の最後から7文字目~5文字目に数字があることがわかっていることを前提に書いていますので、
num=file_name[0][Nstr-7:Nstr-4]
という形で指定しています。
ここはあなたが使用したいファイル名に応じて数字を書き換えてください。
なお、今回はファイル名から数字を取得、その数字の行数、列数を持った配列を作成する、という処理を行っています。
サンプルコードの実行結果
それでは先ほどのコードを実行してみましょう。
冒頭にも紹介したように今回はtestfile_case200.csvというファイルを対象に実行します。
ですので200という数字を使えていれば成功ですね。
実行すると以下の結果が出力されました。
まずは最初のプリントの結果です、。

ここでファイル名を確認しています。
次のプリントの結果です。。
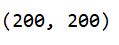
プログラム上で200という数値は一度も入力していませんが、問題なくファイル名についている200という数値を使えていますね。
おわりに
というわけで今回はpythonでファイル名に使われている数字を抜き出してプログラム上で使用する方法をご紹介しました。
意外と使えるスキルですので、データ処理の際などにぜひご活用ください。
このように、私のブログでは様々なスキルを紹介しています。
今は仕事中で時間がないかもしれませんが、ぜひ通勤時間中などに他の記事も読んでいただけると嬉しいです。
⇒興味をもった方は【ヒガサラ】で検索してみてください。
確実にスキルアップできるはずです。
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント