


画像認識のAIについて勉強してるんだけど正直なにをやっているかよくわからない。
この記事では、こんな悩みを解決していきます。
以前、私もAIの講師から
「画像認識のプログラムではこんなことをやってるんだよ~」
とざっくり説明を受けたことはありますが、聞いた当初ははっきりいって全く意味がわかっていませんでした。
ですが、業務でAIに触れているうちにある程度は理解できてきたので、初心に戻って丁寧に解説していこうと思います。
なおこの話は、以下の記事の内容を理解できていることを前提に進めていきます。
まだ、読まれていない方は、まずはそちらからご覧いただければと思います。
また、今回の解説は、一般的なニューラルネットワークを用いた画像認識についてご紹介していきます。
畳み込みニューラルネットワークを用いた手法についてはまた別の機会にでもご紹介していこうと思います。
それでは本題である
画像認識AIの内部では何をやっているのか?
についてご紹介していきます。
※この記事はあくまでも概念理解を目的としており、実際の計算で行われていることを一部省略しています。完全にこの通りではありませんので、そこはご留意いただければ幸いです。
基本的にはニューラルネットワークを使っているだけ
それではさっそく解説に入っていきましょう。
基本的に画像認識のAIでやっていることは、一般的なニューラルネットワークを用い、ある数値データ(インプットデータ)を複雑な行列計算に放り込んで、別の数値データ(アウトプットデータ)を出力しているだけです。
※先ほども少し説明しましたが、この行列計算というところがよくわからない人は以下の記事をまず読んでみましょう。
では、次はこれらのインプットデータとアウトプットデータとは何のことなのかを解説していきます。
画像認識におけるインプットデータ
まずはインプットデータとは何かについて解説していきます。
今回は画像認識の領域でよく使われるデータセットであるMNISTの手書き文字データを用いて解説していきます。
以下のような手書きの文字があったとします。
(MNISTのデータセットの中にはこんな画像が大量に入っています。)
基本的にはこの1枚の画像がインプットデータになります。
(大量の画像をまとめて放り込むわけではありません。あくまで1枚の画像です。)

というわけでこの1枚の画像を以下のようなニューラルネットワークの形に放り込むわけですが、画像がこれらの球の中に入っていくって、ちょっとイメージしにくいですよね。
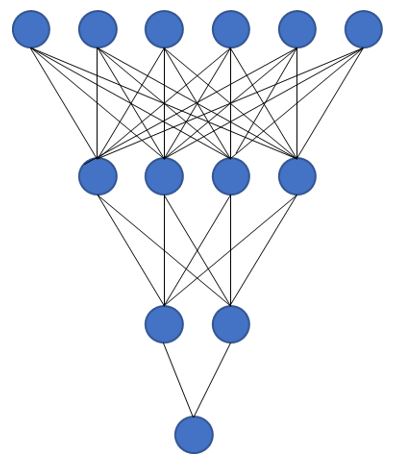
ここはつまづきやすいポイントだと思いますので、解説しておきます。
ここでやることとしては、まず先ほど紹介した7の画像を以下のように縦1ピクセルの画像に変換します。
もとの画像(28×28ピクセル)
変換後の画像(1×784ピクセル)
![]()
(なんかよくわからん破線になりました。)
もとの画像は縦28ピクセル、横28ピクセルなので、縦1ピクセルに変換すると横が784ピクセルの画像になっています。
横にずら~っと並んだこの画像なら、ニューラルネットワークの構造に放り込めそうですよね。
具体的に今回の事例にあてはめてみると、インプットデータの受け皿として784個の球を準備しておいて、その球の中にそれぞれのピクセルの情報を放り込んでいくわけです。
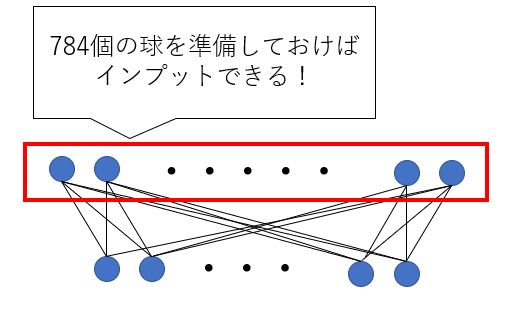
要はニューラルネットワークのインプットの層の球の数を、画像の総ピクセル数分準備しておけば、画像をニューラルネットワークに放り込むことが可能になるというわけです。
(この球の数はAIモデルを作るときに自分で指定するものです。この球の数と画像のピクセル数が一致しなければ学習できませんのでご注意ください。)
というわけで画像の情報をニューラルネットワークに放り込むことはできそうだ、ということはわかったと思います。
では、何を放り込むのでしょうか?
ここで放り込む情報とは、画像の輝度値です。
先ほどの画像で言えば、真っ黒のピクセルは0、真っ白のピクセルは1という具合で、画像の各ピクセルの明るさ度合を情報としてインプットすることになります。
この輝度の明るい暗いの分布から、この画像は何の数字なのかをあてに行くわけです。
というわけでここまでが画像認識におけるインプットデータとは何なのか?というお話でした。
画像認識におけるアウトプットデータ
つぎは画像認識のアウトプットは何なのか?というお話に移ります。
画像認識におけるアウトプットとは、あらかじめ準備された選択肢に対して、与えられたデータが当てはまる確率だと思えばOKです。
例えば、さきほど紹介したような数字の分類問題でいれば、これから出される画像は0~9までの数字のどれかですよ~という10個の選択肢を与えておきます。
そしてAIは複雑な行列計算を経て、
0である確率は **%
1である確率は **%
2である確率は **%
・・・
9である確率は **%
という形で、与えられたデータがそれぞれの選択肢にあてはまる確率を算出します。
そしてそれらの確率データの中からもっとも大きな確率として算出されたものを、選択し、この画像の数字は**です。
というように結果を返して生きてくれます。
これを絵で表すと以下のような感じです。
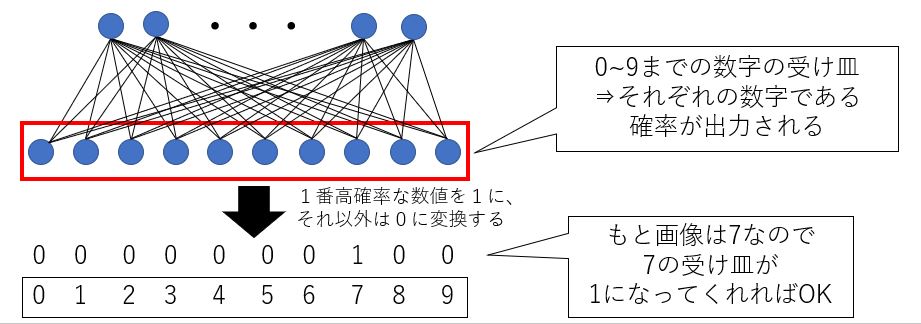
まぁ最後の1に変換してどうたらこうたらという部分は深く考えなくてもOKです。
基本的には先ほども言った通り、あらかじめ準備された選択肢に対して、与えられたデータが当てはまる確率を出していると考えておけばOKです。
これは言い換えると、与えられた数値以外は出力できないということも意味しています。
つまり今回の事例で言うと、0~9までを完璧に分類できるAIがあったとしても、10なんかの選択肢にない数字がきてしまったら、10であると答えることはできないのです。
あなたが分類したい対象に応じて、アウトプットデータの形は調整する。
このことは必ず覚えておきましょう。
インプットとアウトプットの間で行われていること
ここまでで、インプットとアウトプットがざっくりと何なのかがわかったと思います。
最後は、インプットからアウトプットに向かうまでの中間層でどのような計算が行われているのかを具体的に解説していきます。
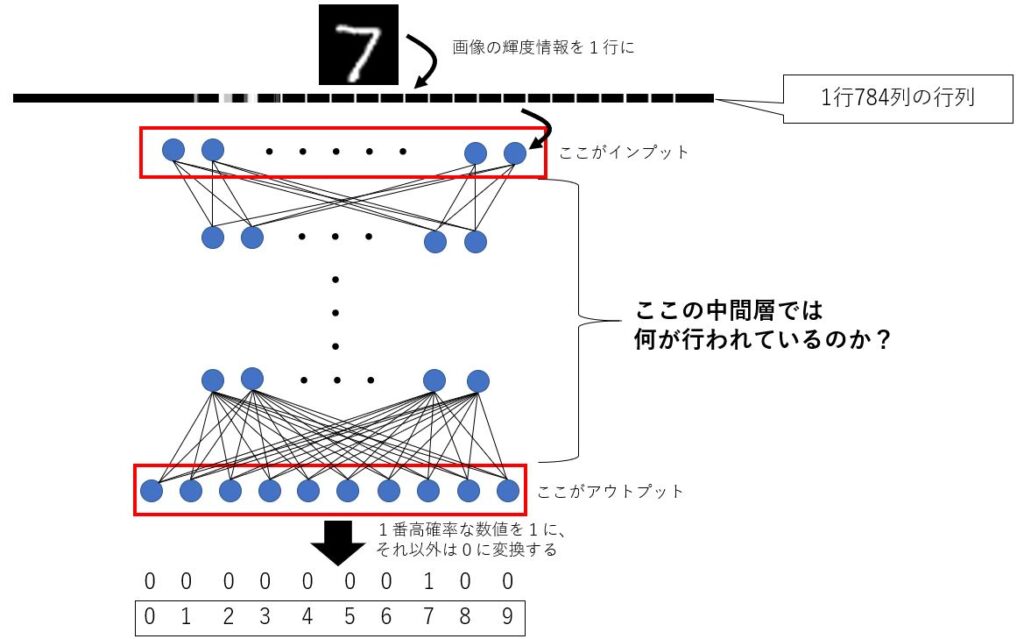
インプットとアウトプットの形は、データの形式やどのようなことを出力するAIにするかでほとんど決まっていますが、それらの間の層は基本的にあなたがチューニングしていくところです。
この中間層では、基本的には行列の計算を行っていくわけですが、最後のアウトプットの数にさえ一致していればどんなチューニングをしてもOKです。
さきほどまでの例で解説します。
MNISTの手書き文字の場合、
インプットデータは784個の輝度データ、
アウトプットデータは10個の分類結果です。
つまり784個の数値が最終的になにかしらの10個の数値になれば良いのです。
例えば以下の画像のような計算をすればOKです。
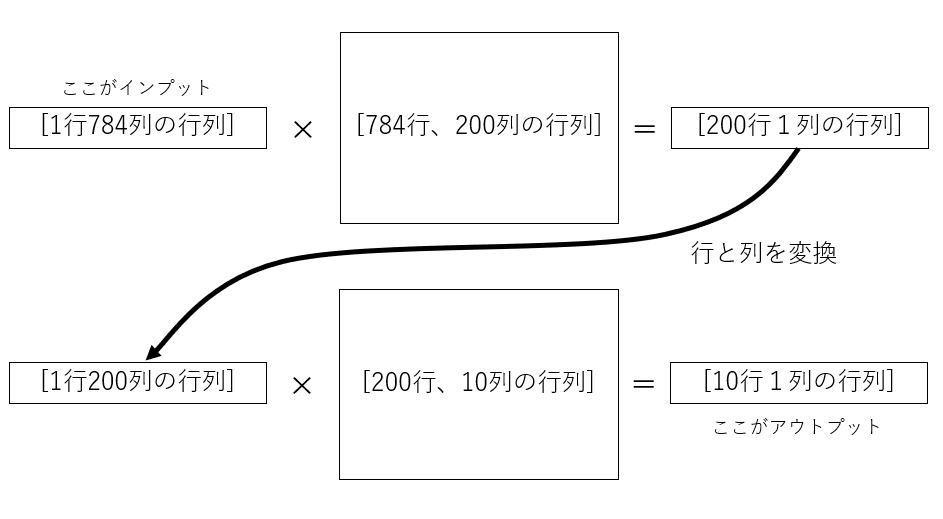
こんな感じできちんと行列計算が正しく行える形で間で積をとる行列を準備してあげれば、インプットとなる784個の数値データからアウトプットとなる10個の数値データに変換できることがわかると思います。
これはあくまでも一例です。
もっと層を増やしたければ、784⇒400⇒200⇒100⇒10みたいにしてもいいですね。
(まぁこの変はKerasとかのライブラリを使えば何も考えずにできるので、ざっくり概念だけ理解できていればOKです。)
いずれにせよ、インプットとアウトプットの形が、準備されているものと一致するように行列の計算が行われている、ということを理解しておきましょう。
ここまでがざっくりとニューラルネットワークの中でどんなことが行われているかの解説でした。
また、AIが学習するということは、先ほどの絵の中に出てきた積をとる行列の中身をいろいろといじくっていくことを意味しています。
このあたりの話は、また次回以降にでもご紹介しようと思います。
おわりに
というわけで今回は、画像認識のAIの内部ではどのようなことが行われているのかを初心者向けに解説してきました。
あなたのAI学習において、何かの役に立っていれば幸いです。
※この記事はあくまでも概念理解を目的としており、実際の計算で行われていることを一部省略しています。完全にこの通りではありませんので、そこはご留意いただければ幸いです。
このように、このブログでは、AI関係のことから、pythonやVBAの使い方まで、幅広くご紹介しています。
ぜひ通勤中なんかに他の記事も読んでもらえると嬉しいです。
⇒興味がある方は【ヒガサラ】で検索!
最後に、この記事が役に立ったという方は、ぜひ応援よろしくお願いします。
↓ 応援ボタン
![]()
にほんブログ村
それではまた!
Follow @HigashiSalary


コメント